
Introduction to Big Data
Big data is a combination of structured, semi-structured, and unstructured data that organizations collect, analyze, and mine for information and insights. It is used in machine learning projects, predictive modeling, and other advanced analytics applications.
Systems that process and store big data have become common components of organizations’ data management architectures. These are combined with tools that support the use of big data analytics. Big data is often characterized by three advantages:
- Large amounts of data in multiple environments.
- Big data systems often store different types of data.
- Speed up data generation, collection, and processing.
Types of Big Data
Big Data is essentially classified into three types:
- Structured Data
- Unstructured Data
- Semi-structured Data
The three types of big data mentioned above can technically be applied at any level of analysis. When working with large amounts of big data, it is important to understand the source of the raw data and its processing before analysis. With so much data, extracting information to get the most out of it must be efficient. The ETL process is different for each data structure.
Structured data
Structured data is the easiest to work with because it is highly organized. Its dimensions are defined by the configured parameters. All the information is grouped into rows and columns, like a spreadsheet. Structured data includes quantitative data such as age, contact information, address, bills, expenses, and debit or credit card numbers.
The quantitative nature of structured data makes it easier to classify and aggregate data programmatically. Processing structured data requires little or no preparation. All you have to do is clean the data and truncate it to the relevant point. You do not need to transform or interpret your data deeply to perform proper testing.
Structured data follows a road map to specific data points or schemas that outline the location of each piece of data and its meaning.
A streamlined process of merging enterprise and relational data is one of the benefits of structured data. Since the relevant data dimensions are defined and in a uniform format, little preparation is required to make all sources compatible.
In the structured data ETL process, the final product is stored in a data warehouse. The initial data is collected for specific analytical purposes, and the database is highly structured and filtered for this purpose. However, the amount of structured data available is limited and represents a small portion of all existing data. According to consensus, structured data accounts for less than 20% of all data.
Unstructured data
Not all data is structured and well categorized with instructions for use. All unorganized data is known as unstructured data.
Almost everything generated by computers is unstructured data. The time and effort required to make unstructured data readable can be burdensome. To get real value from your data, the dataset needs to be interpretable. But the process of making it happen can be far more rewarding.
The hard part of unstructured data analysis is teaching an application to understand the information it is extracting. Translation into a structured format is often required, but this is not trivial and depends on the format and the end goal. Translation can be achieved using text analysis, NLP and development of content hierarchy through classification. Complex algorithms are required to combine the scanning, interpretation, and contextualization processes.
Unlike structured data, which is stored in a data warehouse, unstructured data is stored in a data lake. A data lake stores data and all its information in its raw form. Unlike a data warehouse, where your data is limited to a defined schema, a data lake makes storing your data more flexible.
Semi-structured data
Semi-structured data is somewhere between structured and unstructured data. It is mainly converted into unstructured data with metadata attached. Semi-structured data such as location, time, email address, and device ID stamp can be inherited. It can also be a semantic tag that is later added to the data.
Consider the example of email. The time the email was sent, the email addresses of the sender and recipient, the IP address of the device sending the email, and other relevant information are attached to the email content. Although the actual content itself is unstructured, these components allow you to group data in a structured way.
With the right dataset, you can turn semi-structured data into a valuable asset. Associating patterns with metadata can aid in machine learning and AI training.
The lack of a set schema for semi-structured data is both an advantage and a challenge. It can be difficult to put all your effort into telling your application what each data point means. But at the same time, structured data is open in terms of ETL definition.
Data subtype
Volume
The amount of data matters. Big data requires processing large amounts of low-density, unstructured data. This could be data of unknown value, such as the X (formerly known as Twitter) data feed, clickstreams on web pages or mobile apps, or sensor-enabled devices. Depending on your organization, this can amount to tens of terabytes of data. For others, it may be hundreds of petabytes.
Velocity
Velocity is the speed at which data is received and (supposedly) processed. Streaming data directly to memory is usually faster than writing it to disk. Some Internet-enabled smart products operate in real time or close to real time, requiring real-time assessment and action.
Variety
Diversity refers to the different types of data available. Traditional data types are structured and fit well into relational databases. With the rise of big data, new unstructured data types are emerging. Unstructured and semi-structured data types such as text, audio, and video require additional preprocessing to derive meaning and support metadata. In addition to the three types listed above, there are several subtypes of data that are not officially considered big data but are somewhat relevant to analytics. In most cases, this is a data source such as social media, machines (operational logs), event triggers, geospatial, etc. It can also be open (open source) or linked (web data sent via API or other connection methods). Or in the dark or lost (silent within the system so that it cannot be accessed from the outside, such as the access level of a CCTV system). This may be related. Example:
The Three “Vs” of Big Data
The Value—and Truth—of Big Data
In recent years, two more versus have emerged: value and authenticity. Data has intrinsic value. But it is useless unless its value is known. It is equally important to know how true the data is and how much you can trust it.
Today big data has become capital. Consider the world’s largest technology companies. A large part of the value they provide comes from data, which they continuously analyze to increase efficiency and develop new products.
Recent technological advances have significantly reduced the cost of data storage and computing, making it easier and cheaper than ever to store more data. Large amounts of big data have become cheaper and more accessible, making it possible to make more accurate and precise business decisions.
Finding value in big data isn’t just about analyzing the data, which has many other benefits. It’s an exhaustive discovery process that requires insightful analysts, business users, and executives to ask the right questions, recognize patterns, make informed assumptions, and predict behavior.
The History of Big Data
Although the concept of big data is relatively new, the origins of big data sets date back to the 1960s and 1970s, when the world of data took off with the development of the first data centers and relational databases.
Around 2005, people began to realize how much data users were generating through Facebook, YouTube, and other online services. Hadoop, an open-source framework built specifically for storing and analyzing large data sets, was also developed in the same year. NoSQL also started gaining popularity around this time.
The development of open source frameworks like Hadoop (and more recently Spark) has been essential to the growth of big data, as they make it easier to manipulate and cheaper to store. Since then, the volume of big data has skyrocketed. Users are still generating large amounts of data, but they are not alone in doing so.
With the advent of the Internet of Things (IoT), more objects and devices are connected to the Internet and data is collected about customer usage patterns and product performance. With the advent of machine learning, even more data has been generated.
What is machine learning? You did know know.
Big Data has come a long way, but its usefulness is just beginning. Cloud computing has further expanded the possibilities of big data. The cloud offers truly elastic scalability, allowing developers to test a subset of their data by simply launching an ad-hoc cluster. Equally important are graph databases that can display large amounts of data in a way that makes analysis quick and comprehensive.
What is cloud computing? Everything is here.
Big Data Benefits
- Big data allows us to get more complete answers because we have more information.
- More complete answers means more reliable data. This means a completely different approach to dealing with the problem.
Product development
Companies like Netflix and P&G use big data to predict customer demand. Create predictive models for new products and services by classifying key characteristics of past and present products and services and modeling the relationship between those characteristics and the commercial success of the product. Additionally, P&G uses data and analytics from focus groups, social media, test markets, and initial store deployment to plan, produce, and launch new products.
Predictive maintenance
The factors that can predict mechanical failure are deeply embedded in structured data such as equipment year, make and model, as well as unstructured data covering millions of log entries, sensor data, error messages and engine temperatures. . By analyzing signs of potential problems before they arise, organizations can more cost-effectively deploy maintenance and maximize the uptime of parts and equipment.
Customer experience
The race to add customers has started. You now have a clear picture of your customer experience. Big data allows you to collect data from social media, web visits, call logs and other sources to improve interaction experiences and maximize the value provided. Start delivering personalized offers, reduce customer churn, and handle issues proactively.
Fraud and compliance
When it comes to security, you have to fight not just a few rogue hackers but an entire team of experts. The security environment and compliance requirements are constantly evolving. Big data can help identify patterns in data that indicate fraudulent activity and aggregate large amounts of information for faster regulatory reporting.
Machine learning
Machine learning is a hot topic right now. Data, especially big data, is one reason for this. Now we can teach machines instead of programming them. The use of big data to train machine learning models makes this possible.
Know details about machine learning
Operational efficiency
Operational efficiency isn’t necessarily in the news, but it is one area where big data is having the biggest impact. Big data allows you to analyze and evaluate production, customer feedback and returns, and other factors to minimize outages and predict future demand. Big data can also be used to improve decision-making in line with current market demands.
Drive innovation
Big data helps drive innovation by studying the interdependencies between people, organizations, institutions, and processes and determining new ways to use those insights. Use data insights to improve financial and planning decisions. Research trends and what new products and services customers want introduced. Implement dynamic pricing. There are endless possibilities.
Big Data Challenges
Big Data holds a lot of promise, but it is not without challenges.
First of all, big data is… Although new technologies for data storage are being developed, the amount of data is doubling approximately every two years. Organizations are still struggling to find ways to retain data and store it effectively.
But just storing data is not enough. To make data valuable, you need to use it, and this depends on curation. Clean data—data that is relevant to the customer and organized in a way that allows meaningful analysis—requires a lot of work. Data scientists spend 50–80% of their time collecting and preparing data before actually using it.
Ultimately, big data technology is changing rapidly. A few years ago, Apache Hadoop was a popular technology used to process large amounts of data. Then, in 2014, Apache Spark was introduced. A combination of the two frameworks is currently considered the best approach. Keeping up with big data technology is an ongoing challenge.
How Big Data Works
Big data provides new insights that open up new opportunities and business models. There are three key actions required to get started:
1. Integrate
Big data brings together data from many different sources and applications. Traditional data integration mechanisms such as extract, transform, and load (ETL) are usually not up to the task. Analyzing large data sets at terabyte and even petabyte scale requires new strategies and technologies.
During integration, you must ingest and process the data to ensure that it is formatted and available in a format that business analysts can start with.
2. Manage
Big data requires storage. Storage solutions can exist in the cloud, on-premises, or both. You can store your data in any format and deploy the necessary processing requirements and process engines on those data sets on demand. Many people choose storage solutions based on where their data currently resides. The cloud is gradually becoming more popular because it supports current computing requirements and allows resources to be launched on demand.
3. Analyze
Investing in big data works by analyzing and acting on data. Gain new clarity by visually analyzing different datasets. Explore your data further and make new discoveries. Please share what you discover with others. Build data models using machine learning and artificial intelligence. Put your data to work.
What is artificial intelligence?
Top 10 opportunities of big data
1. Information management
Big data enhances the discovery, access, availability, exploitation, and provision of information within enterprises and supply chains. This allows you to discover new datasets that have not been used yet to increase your value.
2. Boost maintenance and operational effectiveness
Better modeling enabled by big data analytics enables more accurate decision-making, sustained productivity gains through automation, lean operations, and optimized services through predictive analytics.
3. Boost supply chain visibility and transparency
Regardless of the location of the data, big data can increase supply chain visibility and transparency through real-time control and multi-layer (process, decision, and financial) visibility. According to the study’s experts, the impact of increased availability of company information on supply chain visibility and transparency is the second most relevant opportunity at the company level.
4. Better accountability
Big Data enables businesses to react quickly to changing market conditions by gaining visibility and deeper understanding of the information-rich ecosystem. This improves real-time response to customer needs and changing market conditions, reducing time to market and improving supply chain robustness.
5. Strength in product and market strategies
Big data analytics enhances customer segmentation, increases scalability and enables personalization at scale. This allows you to improve your customer service levels, enhance your customer acquisition and sales strategies (via web and social), and even optimize your delivery.
6. Improve demand management and production planning
Large-scale analytics provide insight into product launch and release planning, and increased planning level granularity enables optimized, shorter planning cycles.
7. Benefits of Innovation and Product Design
A wide variety of data streams aid innovation and product design. These include leveraging product usage data, point-of-sale data, field data from equipment, customer data, and supplier recommendations to drive product and process innovation.
8. Positive financial impact
Big data can reduce long-term costs, increase investment efficiency and improve understanding of cost drivers and impacts.
9. More integration and collaboration
Big data enables better integration and collaboration within the supply chain. Adopting a cross-functional integration and collaboration approach with key partners helps build a culture of trust, enabling higher levels of information sharing and helping to optimize the entire supply chain ecosystem.
10. Strengthening logistics
Data-enabled product traceability reduces lead times, for example, due to the handling of goods in transit. It enables real-time scheduling, route planning, rerouting and roadside service planning.
Big Data Solution
Before deciding to invest in a big data solution, evaluate what data is available for analysis, what potential insights can be gained from exploring the data, and how to define, develop, and implement a big data platform. Resources required to create and implement. When talking about big data solutions, the right questions are a great starting point. You can use the questions in the article as a checklist to guide your research. The questions and their answers begin to uncover the data and the problem.
Companies may have some idea of what type of information they need to review, but the details may not be as clear. Data may provide clues to previously undiscovered patterns, and if patterns are found, the need for further research becomes apparent. First, let’s create some simple use cases. By doing so, we will be able to collect and retrieve data that was previously inaccessible, which will help us discover these unknowns. A data scientist’s ability to identify important data and develop practical forecasting and statistical models improves as data repositories are established and more data is collected.
It is also possible that companies are aware of information gaps within their companies. Identifying external or third-party data sources and implementing certain use cases that rely on this external data is the first step in addressing these known and unknown issues. To do this, companies need to work with data scientists.
Before focusing on dimension-based strategies that can help analyze the sustainability of a company’s big data solutions, this article will discuss some of the issues that most CIOs often express before launching big data initiatives. . Its purpose is to clarify this.
What Are the Key Steps in Big Data Solutions?
A big data analytics solution requires the following steps:
- Data Ingestion: The first step in deploying a big data solution is to ingest data from a variety of sources, including ERP systems like SAP, customer relationship management systems like Salesforce and Siebel, and relational database management systems (RDBMS). MySQL. It’s about collecting. Oracle, or log files, flat files, documents, images, social media feeds, etc. HDFS is needed to store this information. Data can be received once a day, once an hour, or once every 15 minutes using batch tasks or real-time 100ms to 120s streaming.
- Data storage: Once the data is ingested, it should be stored in a NoSQL database such as HDFS or HBase. The HBase file system is designed for random read/write access, while the HDFS file system is suitable for sequential access.
- Data Processing: Ultimately, you will pass your data through some processing framework (MapReduce, Spark, Hive, etc.).
Best Big Data Solutions
The following is our list of top big data solutions based on a thorough analysis of features and benefits:

Apache Hadoop
Overview
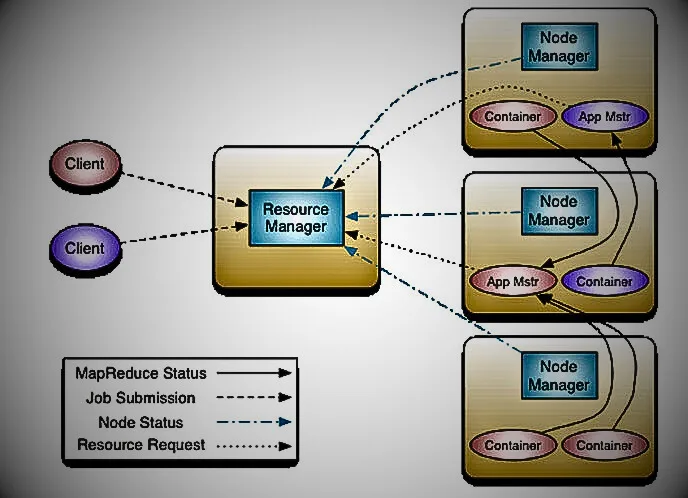
Apache Hadoop is a free, open-source, distributed file system built to enable lightning-fast processing of big data stored in clusters and scale to meet enterprise requirements. It can be deployed in the cloud and on-premises, and supports NoSQL distributed databases (such as HBase), allowing you to spread your data across thousands of servers with little or no impact on performance. Its components include the Hadoop File Distribution System (HDFS) to enable storage, MapReduce to handle data processing, and Hadoop YARN (short for Yet Another Resource Negotiator) to manage computing resources in the cluster.
Top Benefits
Reliable data access: With support for file sizes ranging from gigabytes to petabytes stored across multiple systems, data replication ensures reliable access to sensitive information. Cluster-wide load balancing involves evenly distributing data across disks and supports low-latency data retrieval.
- Local data processing: Hadoop enables parallel processing of local data by distributing files across different cluster nodes and forwarding packaged code across those nodes.
- Scalability: Provides high scalability and availability for your business by detecting and handling failures at the individual application level. New YARN nodes can join the resource manager to run jobs, and nodes can be retired seamlessly to downscale the cluster.
- Centralized cache management: Users can obtain the data blocks needed for software caches on individual nodes by specifying a path from a central system. Explicit pinning allows users to keep a limited number of block-read replicas in the buffer cache, and the rest are discarded to optimize memory usage.
- File system snapshots: point-in-time snapshots of the file system record block lists and file sizes, but Hadoop ensures data integrity by not copying the actual data. It records changes to the file system in chronological order, making current data easy to access.
Primary Features
- Programming framework: This framework enables developers to create data processing applications that enable computing jobs to run on multiple cluster nodes. Users can perform a rolling upgrade of the MapReduce framework by running a different version than the originally deployed version through distributed cache deployment.
- Native components: The Hadoop library includes components that are deployed natively to improve performance, such as native IO utilities for purposes such as compression codecs, centralized cache management, checksum implementation, etc.
- HDFS NFS Gateway: Enables local browsing of HDFS files with options to mount HDFS as part of the client’s local file system and to download and upload files to and from the local file system.
- Memory storage support: HDFS supports writes to off-heap memory, flushing in-memory data to disk, and keeping performance-critical IO paths clear. These data offloads, called lazy persist writes, help reduce query response latency.
- Extended attributes: Users can link additional metadata to files or directories through extended attributes to store additional information about the application inode.
Limitations
- Real-time data processing is not supported; only batch processing is supported. As a result, overall performance is reduced.
- It does not support periodic data flows, so it is not very efficient for repetitive processing.
- Data encryption is not implemented at the storage and network levels. We use Kerberos authentication as a security measure that is difficult to maintain.
Apache Spark
Overview
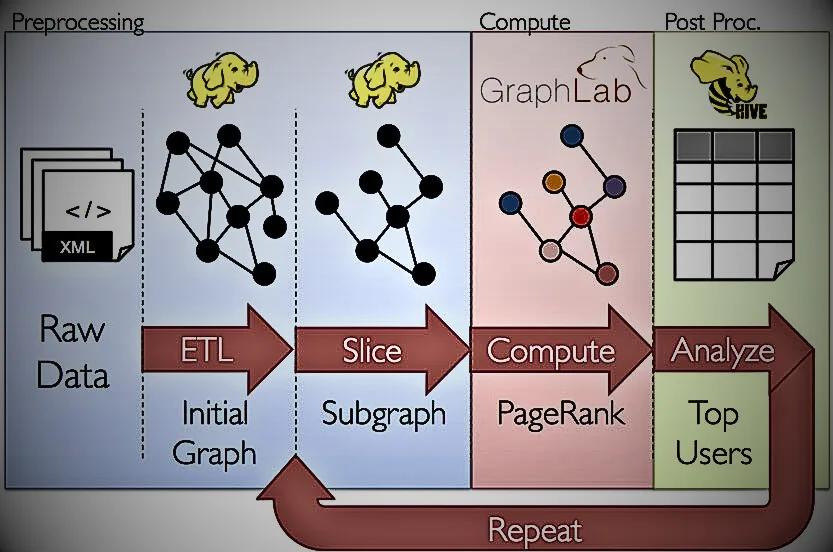
Apache Spark is an open-source computing engine that can perform batch processing as well as real-time data processing, making it clearly superior to Hadoop. Spark’s “in-memory” computing is the key to its lightning-fast computing speed, where intermediate data is stored in memory, reducing the number of read/write operations to disk. Built to power the Hadoop stack, it is supported in Java, Python, R, SQL, and Scala. By extending the MapReduce model, Spark seamlessly processes interactive queries and stream processing faster than the speed of thought.
Top Benefits
- Deploy: In addition to running on Apache Mesos, Yarn, and Kubernetes clusters, Spark is deployed as a standalone that can be started manually or via a startup script. Users can run different daemons on the same machine for testing.
- Spark SQL: With access to Hive, Parquet, JSON, JDBC, and a variety of data sources, Spark SQL enables data queries via SQL or DataFrame APIs. Support for HiveQL syntax, Hive SerDes and UDFs allows you to access your existing Hive warehouse and connect to business intelligence tools.
- Streaming Analytics: Supports efficient batch and stream processing with the ability to read data from HDFS, Flume, Kafka, Twitter, ZeroMQ, and custom data sources, join streams against historical data, and actually receive data. You can also run ad-hoc queries on your data. Time.
- R Connectivity: SparkR is a package that allows users to connect R programs from RStudio, RSHEL, RScript, or other R IDEs to a Spark cluster. In addition to distributed data frames that support selection, filtering, and aggregation of large datasets, MLlib enables machine learning.
Primary Features
- Architecture: In addition to RDDs, the Spark ecosystem includes Spark SQL, Scala, MLlib, and core Spark components. It has a master-slave architecture with driver programs that can run on the master or client node and multiple executors that run on worker nodes in the cluster.
- Spark Core: The core processing engine enables memory management, disaster recovery, scheduling, distribution, and job monitoring on the cluster.
- Abstraction: Spark enables smart reuse of data and variables through flexible distributed datasets (RDDs), which are collections of elements divided into nodes for parallel processing. Users can also request that the RDD be kept in memory for later reuse. Spark provides another abstraction: the sharing and reuse of variables that are used to cache values in memory or act as counters or sums in calculations.
- Machine Learning: Spark provides ML workflows including feature transformation, model evaluation, ML pipeline creation, and more through clustering, classification, modeling, and recommendation algorithms.
Limitations
- Security is turned off by default, which can make your deployment vulnerable to attacks if not configured properly.
- The version does not appear to be backward compatible.
- Occupies a large amount of memory space due to the in-memory processing engine.
- There is no built-in caching algorithm, so you have to configure it manually.
Hortonworks Data Platform
Overview
Yahoo founded Hortonworks in 2011 to accelerate enterprise adoption of Hadoop. Its Hadoop distribution, Hortonworks Data Platform (HDP), is completely open source and free, offering competitive in-house expertise and attractive incentives for companies wishing to adopt Hadoop. It includes Hadoop projects like HDFS, MapReduce, Pig, Hive and Zookeeper. HDP is known for its purist approach to open source and does not come with any proprietary software. It is completely open source, powered by Ambari for management, Stinger for query processing, and Apache Solr for data retrieval. HCatalog is an HDP component that allows you to connect Hadoop to other enterprise applications.

Top Benefits
- Deploy anywhere: on-premises, in the cloud (as part of Microsoft Azure HDInsight), and deploy with Cloudbreak, a hybrid solution. Cloudbreak is designed for enterprises with existing on-premises data centers and IT infrastructure, providing elastic scaling to optimize resources.
- Scalability and high availability: Enterprises can use NameNode federation to scale to thousands of nodes and billions of files. NameNodes manage file paths and mapping metadata, and federation ensures that they are independent of each other, ensuring high availability with a low total cost of ownership. Additionally, erasure coding significantly improves storage efficiency and enables more efficient data replication.
- Security and governance: Apache Ranger and Apache Atlas enable tracking of data lineage from its origin to the data lake, enabling a strong audit trail for the governance of sensitive information.
- Faster time to insights: This enables businesses to deploy applications within minutes, reducing time to market. You can incorporate machine learning and deep learning into your applications through graphics processing units (GPUs). Its hybrid data architecture provides cloud storage for unlimited data in native formats such as ADLS, WASB, S3, and GCP.
Primary Features
- Centralized architecture: By using Apache YARN for the backend, Hadoop operators can scale their big data assets as needed. YARN seamlessly allocates resources and services to applications distributed across clusters for operation, security, and governance. It allows businesses to analyze data received from multiple sources and in different formats.
- Containerization: Built-in YARN support for Docker containers allows third-party applications to be rapidly deployed and run on Apache Hadoop. Users can run and test multiple versions of the same application without affecting the existing application. Add to this the inherent benefits of containers (resource optimization and increased work throughput), and you have a competitive product.
- Data access: YARN allows different data access methods to co-exist within the same cluster for shared data sets. HDP takes advantage of this functionality to allow users to work with different data sets simultaneously in different ways. It allows business users to manage and process data within a single cluster, eliminating data silos through interactive SQL, real-time streaming, and batch processing.
- Interoperability: HDP was built from the ground up to provide enterprises with a pure open-source Hadoop solution that can be easily integrated with a wide range of data center and BI applications. Businesses can connect their existing IT infrastructure to HDP with minimal effort, saving money, effort, and time.
Limitations
- Does not come with proprietary tools for data management. Organizations require additional solutions for query processing, discovery, and deployment management.
- It is very difficult to implement SSL using a Kerberos cluster.
- You cannot add security restrictions to data on Hive, which is an HDP component.
Vertica Advanced Analytics Platform
Overview
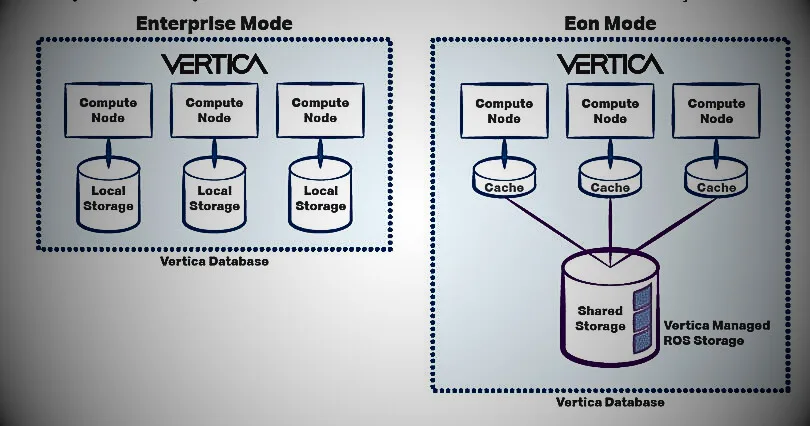
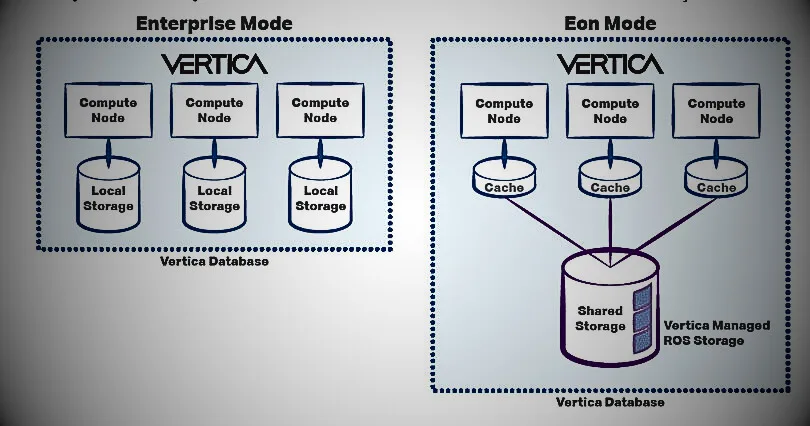
Part of Hewlett Packard Enterprises (HPE) since 2011, Vertica became part of Micro Focus following the 2017 merger between Micro Focus and Apache. Both Hadoop and Vertica Analytics platforms are scalable big data solutions with massive parallelism, but Vertica is next-generation relational. Database platform with standard SQL and ACID transactions. These two often complement each other in business solutions, with Hadoop providing batch processing and the Vertica Analytics platform enabling real-time analytics. They work together through several connectors, including a bidirectional connector for MapReduce and an HDFS connector for loading data into the Vertica Advanced Analytics Platform.
Top Benefits
- Resource management: Users can run workloads simultaneously at an efficient pace through resource managers. It not only reduces CPU and memory usage and disk I/O processing time but also compresses data size up to 90% without losing information. A massively parallel processing (MPP) SQL engine provides active redundancy, automatic replication, failover, and recovery.
- Flexible deployment: a high-performance analytical database that can be deployed on-premises, in the cloud, or as a hybrid solution. It is flexible, scalable, and built to run on Amazon, Azure, Google, and VMware clouds.
- Data management: columnar data storage makes it ideal for read-intensive workloads. Vertica supports a variety of input file types with upload speeds of several megabytes per second per machine and per load stream. Control data quality through data locking when multiple users access the same data simultaneously.
- Integration: Helps analyze data from Apache Hadoop, Hive, Kafka, and other data lake systems through built-in connectors and standard client libraries, including JDBC and ODBC. It integrates with BI tools like Cognos, MicroStrategy, and Tableau and ETL tools like Informatica, Talend, and Pentaho.
- Advanced analytics: Vertica combines basic database functionality with analytical capabilities such as machine learning, regression, classification, and clustering algorithms. Businesses can leverage out-of-the-box geospatial and time-series analytics capabilities to instantly process incoming data without purchasing additional analytics solutions.
Primary Features
- Data Preparation: Users can load and analyze not only structured data but also semi-structured data sets through Flex Tables.
- On Hadoop: Vertica for SQL installs directly on Apache Hadoop and provides powerful query capabilities and analytics. Read native Hadoop file formats, such as Parquet and ORC files, and write back to Parquet.
- Flattened tables: Analysts can create faster queries and perform complex joins through flattened tables. They are separate from the source tables, so changes made to one table do not affect the other tables. It allows rapid big data analysis on databases with complex schemas.
- Database Designer: The database designer enables performance-optimized design of ad-hoc queries and operational reports using SQL scripts that can be deployed automatically or manually.
- Workload Analyst: Optimize database objects through system table analysis with tuning recommendations and tips. Enables root cause analysis through workload and query execution history, resources, and system configuration.
Limitations
- Enforcing foreign keys and referential integrity is not supported.
- Automatic constraints are not supported on foreign tables.
- Removal takes time and may delay other processes in the pipeline.
Pivotal Big Data Suite
Overview
Pivotal Big Data Suite is an integrated data warehousing and analytics solution owned by VMWare. Pivotal HD’s Hadoop distribution includes YARN, Gem Fire, SQL Fire, and Gem Fire XD, an in-memory database with real-time analytics capabilities on top of HDFS. It has a full-featured REST API and supports SQL, MapReduce parallelism, and data sets up to hundreds of terabytes.
Pivotal Greenplum is cloud agnostic and deploys seamlessly on public and private clouds, including AWS, Azure, Google Cloud Platform, VMWare, vSphere, and OpenStack. In addition to automated, repeatable deployments with Kubernetes, Cloud Foundry provides stateful data persistence for applications.
Top Benefits
- Open Source: In partnership with the open source PostGreSQL community, all contributions to the Greenplum Database Project share the same MPP architecture, analytic interfaces, and security features.
- High availability: Pivotal Gem Fire has automatic failover to other nodes in the cluster if a job fails. When a node leaves or joins the cluster, the grid is automatically rebalanced and reorganized. WAN replication enables multi-site disaster recovery deployments.
- Advanced Analytics: Pivotal Greenplum is a scalable database with ubiquitous support for R, Python, Keras, and Tensor Flow for machine learning, deep learning, graph text, and statistical techniques. It provides geospatial analysis based on Post GIS, and GP Text provides text analysis using Apache Solr.
- Fast data processing: Gem Fire’s horizontal architecture, combined with in-memory data processing, is designed for low-latency application requirements. Additionally, queries are routed to nodes with relevant data to improve response time, and query results are displayed in a data table-like format for easy reference.
Primary Features
- Architecture: “Shared-nothing” architecture with independent nodes, data replication, and persistent write-optimized disk stores helps reduce processing times.
- Integration: Greenplum integrates with Kafka to provide fast event processing for streaming data through low-latency writes. Enables SQL-based ad-hoc queries and predictive analytics on data stored in HDFS and machine learning through Apache MADlib. It improves data integration in the cloud by properly executing Amazon S3 object queries.
- Scalability: Pivotal helps Gem Fire users maximize efficiency and keep steady-state runtime costs low by allowing them to scale horizontally and re-scale as needed.
- Query Optimizer: A high-speed query optimizer enables accelerated parallel computing on petabyte-sized data sets by selecting the best possible query execution model.
Limitations
- The latest version of Greenplum does not bundle curl and instead loads system-provided libraries.
- MADlib, GPText, and PostGIS are not available on Ubuntu systems.
- Greenplum for Kubernetes is not available in the latest releases.
The importance of big data
Big data won’t destroy your business immediately, but leaving it alone in the long run won’t be the solution. You need to measure the impact of big data on your business so that you can easily determine the return on your investment. Therefore, big data is an issue worth considering.
When you visit a website, you may have noticed that there is a recommendation field on the right panel, top panel, or somewhere on the screen, that contains ads related to your preferences. How does an advertising company know that you are interested in their advertising?
Well, everything you surf on the Internet is saved, and all this data is properly analyzed so that you can see everything that you are surfing and that interests you. You will be interested in that particular advertisement, and you will surf further on the net. But just in case! The amount of data generated by a single user is very large and is called big data.
follow me : Twitter, Facebook, LinkedIn, Instagram
1 thought on “Introduction to Big Data: Challenges, Opportunities, and Solutions 2025”
Comments are closed.