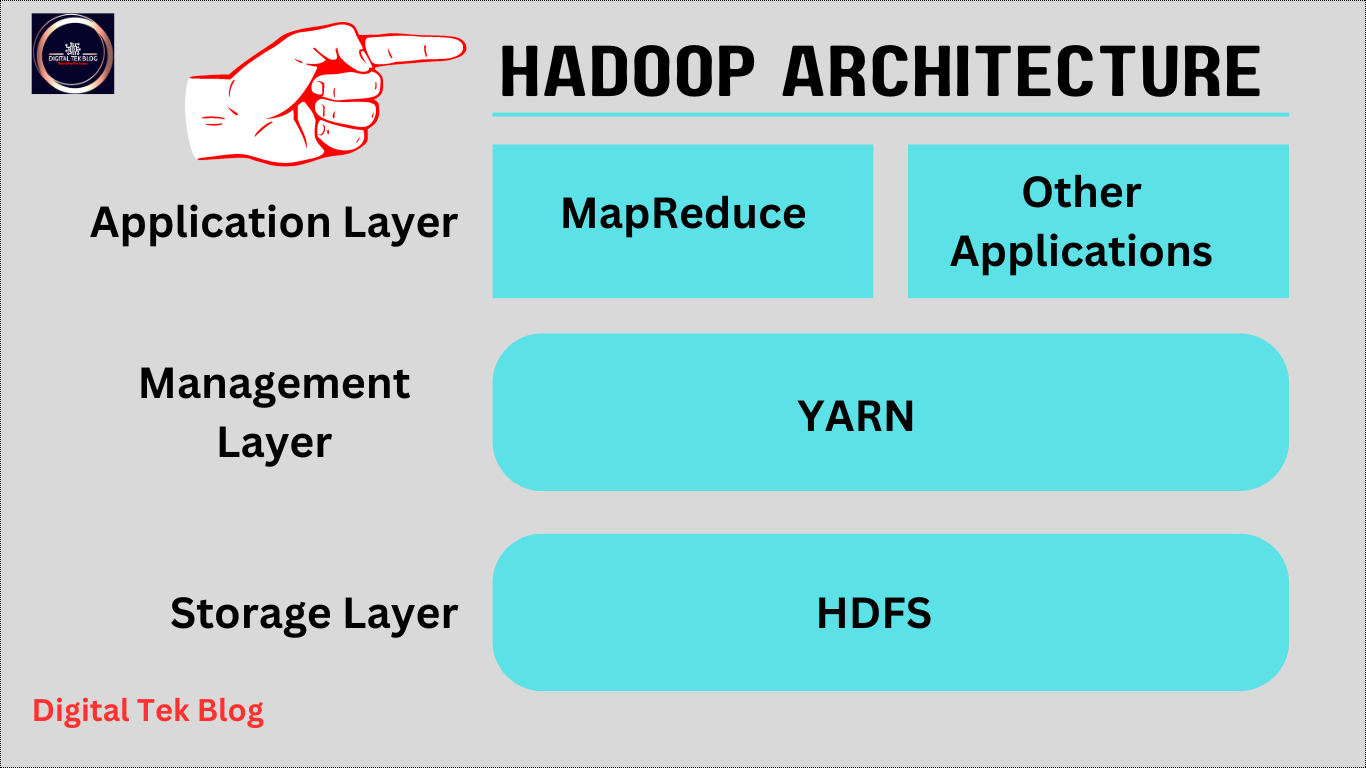
Hadoop architecture is designed for data processing. It is a big challenge to manage system failure, data replication, and large amounts of data storage. Hadoop architecture to handle these types of challenges and manage the task in an easy way. Hadoop architecture is based on HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), MapReduce programming model, and Hadoop Common. In this article, we discussed Hadoop’s definition, architecture, and components.
What is Hadoop?
Hadoop is part of Apache, an open-source framework used to analyze a huge volume of data, like data from websites and social media. Hadoop is written in the Java programming language. It is a software framework for use in data processing. Hadoop was developed by Google in 2002, but it was released in 2009. It is designed to be open-source. Yahoo, Facebook, Twitter, Google, LinkedIn, and many more companies use Hadoop software.
What are the components of Hadoop?
There are four main components of Hadoop:
HDFS
HDFS is called the Hadoop Distributed File System. This is the storage system solution that is essential for highly centralized data centers. Google GFS is a fully distributed file system that performs four times faster than HDFS. HDFS from Google is a popular Hadoop file storage open-source solution. It has the ability to optimize highly volumetric data, and it can track the use of data for future growth. Google approaches GFS for data management and storage solutions. It is easy to use for large-scale data analysis and processing.
YARN (Yet Another Resource Negotiator)
It is used as a resource scheduler for job scheduling and managing the cluster. It is responsible for determining who gets what resource at what time.
MapReduce
MapReduce is an algorithm/data structure that is based on the Yarn framework. MapReduce is the main feature for performing distributed processing in parallel in a Hadoop cluster so that Hadoop can work fast. There are two tasks that MapReduce does: in the first task, map is utilized, and in the second task, reduce is utilized. Hadoop Common: Hadoop is an open-source distributed computing platform that allows you to store and process large amounts of data. Hadoop stores and analyzes the data from different sources, like databases, web servers, and file systems. It is designed to process large amounts of data from computers. It allows us to analyze the data faster and more accurately.
Hadoop Architecture
Hadoop Architecture is a package of MapReduce, HDFS (Hadoop Distributed File System), and file systems. MapReduce can be of two types, either MapReduce/MR1 or Yarn/MR2. Hadoop cluster architecture includes a single master node and multiple slave nodes. The master node performs Job Tracker, Task Perform, NameNode, and DataNode; another way is that the slave node performs DataNode and TaskTracker.
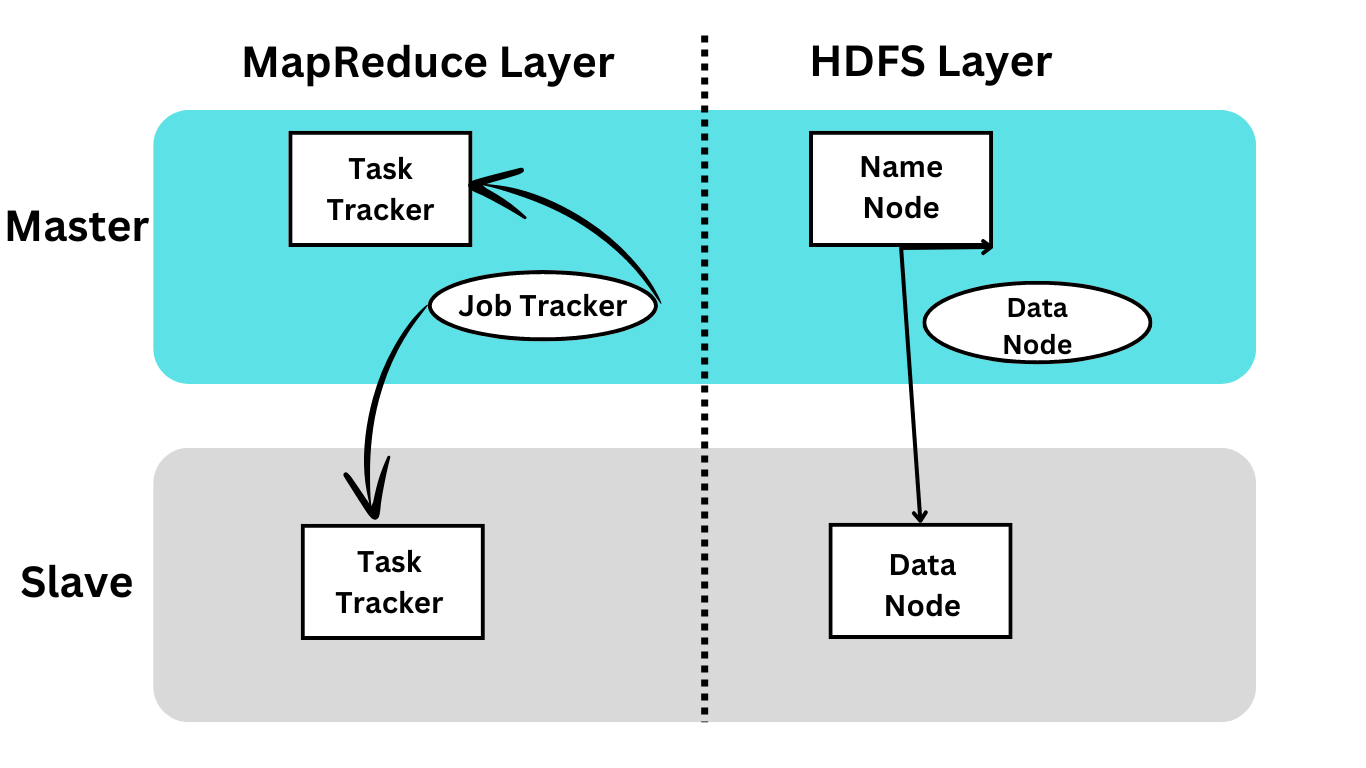
Hadoop Distributed File System (HDFS)
Hadoop Distributed File System contains master/slave architecture. In this architecture, there is a single NameNode and multiple DataNode. Single NameNode performs the master role and multiple DataNode performs the slave role.
HDFS is developed on the Java language platform so that many machines can easily run the NameNode and DataNode.
NameNode
- This exists in the HDFS cluster and role as single master server.
- It manages the namespace of the file system and executes the opening, renaming, and closing of the file system.
DataNode
- Multiple DataNode exists in the HDFS cluster.
- Each DataNode has multiple data blocks.
- The data blocks work by storing the data in each data block.
- The DataNode provides the client with read and write permission.
- It performs deletion, creation, and replication from the DataNode.
Job Tracker
- It accepts the MapReduce jobs from the client and processes the data with the help of NameNode.
Task Tracker
- Works as a slave node for the Job Tracker.
- It performs the task from Job Tracker and applies code to the file system. It is also known as mapper processing.
MapReduce
MapReduce is a software framework for data processing that allows to process of large amounts of data suitably. It allows for partitions of data and processes when it will be needed.
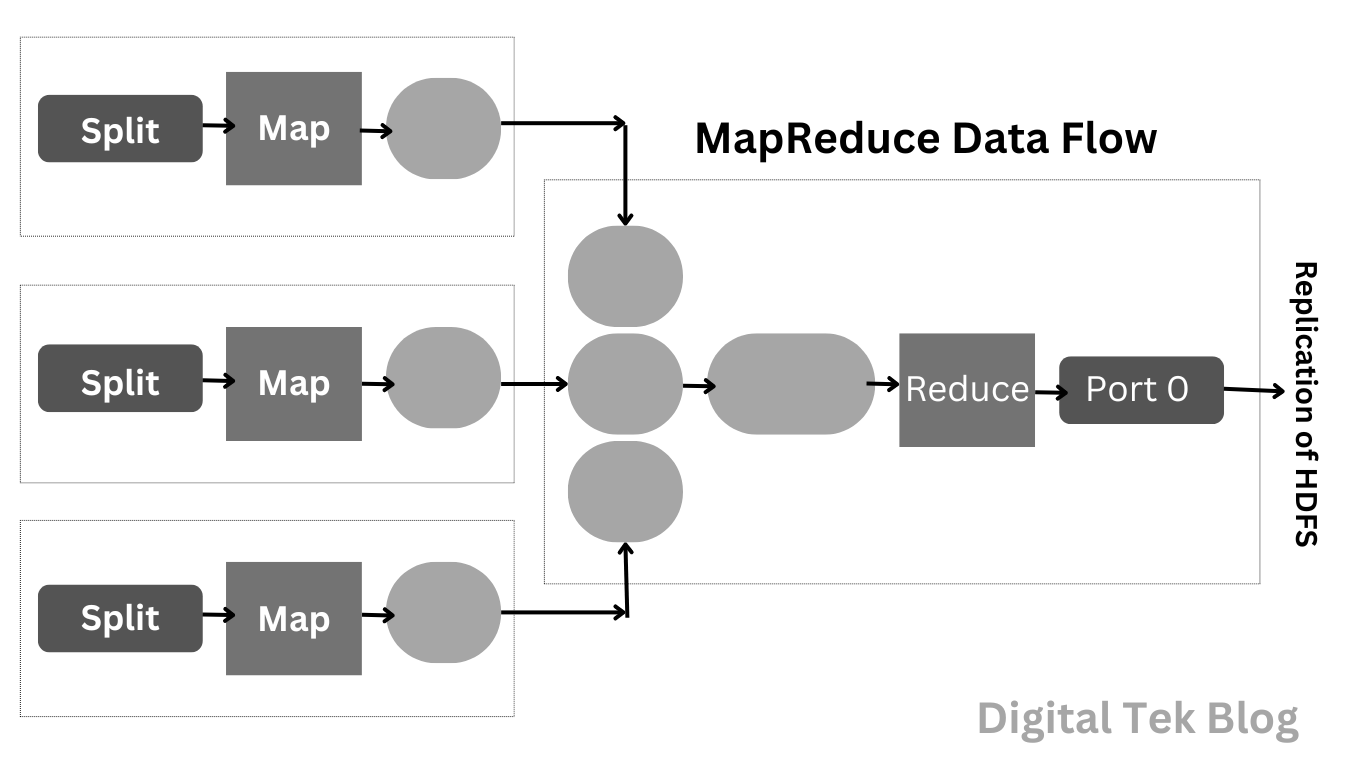
MapReduce Job Execution
- Input data is stored in HDFS and used in the input format.
- The input file size has a default size of 128 MB, but it can be customized manually.
- Data is read by the record reader in input format and forwarded the information to the mapper.
- The mapper provides the data in the list of data elements.
YARN (Yet Another Resource Negotiator)
Yarn is responsible for manage the resources of data in the cluster and provide the scheduling task to the users. It is the main key elements of Hadoop architecture that allow multiple data processing, batch processing, and stored data in the HDFS cluster.
Conclusion
Hadoop is an open-source software framework for data processing. It takes a large amount of data from the database, web server, and batch file and processes it. There are different types of applications in Hadoop, like data warehousing, big data analytics, and cloud computing. Hadoop works together on several components and processes. The main component is MapReduce, which processes the data. MapReduce divides the task into small frameworks, and after the process, it is recombined into large tasks. There is a distributed file system called HDFS that stores a large amount of data.
follow me : Twitter, Facebook, LinkedIn, Instagram