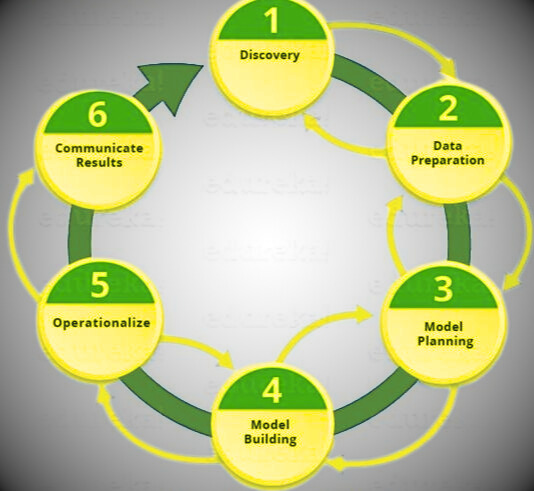
The data science lifecycle revolves around the use of machine learning and various analytical strategies to generate insights and predictions from information to achieve business enterprise goals. The entire method involves several steps, such as data cleaning, preparation, modeling and model evaluation. This is a lengthy process and may take several months to complete. Therefore, it is very important to have a common structure to observe any problem. The globally referenced framework in solving analytical problems is called the Industry Standard Process for Data Mining or CRISP-DM framework.
What is data science, and what does it need?
Previous data is very short and generally accessible in a well-structured format, making it easy and convenient to store it in an Excel sheet, and with the help of business intelligence tools, the data can be processed efficiently. Could. However, today we are dealing with huge amounts of data, with approximately 3.0 quintillion bytes of records generated every day, which will eventually result in an explosion of records and data. Recent research estimates that 1.9 MB of data and records are created every second through a single person.
Therefore, dealing with such a huge amount of data generated every second is a big challenge for any organization. Processing and evaluating this data requires extremely powerful and complex algorithms and technology. This is where data science comes into play.
The main motivations for using data science technology are:
- It helps transform large amounts of raw, unstructured records into valuable insights.
- Useful for various surveys, unique predictions of elections, etc.
- It will also help automate transportation, such as with the rise of self-driving cars, which are the future of transportation.
- Companies are moving towards data science and choosing this technology. Companies like Amazon and Netflix, which process large amounts of data, use informatics algorithms to provide better consumer experiences.
Data Science Life Cycle Diagram
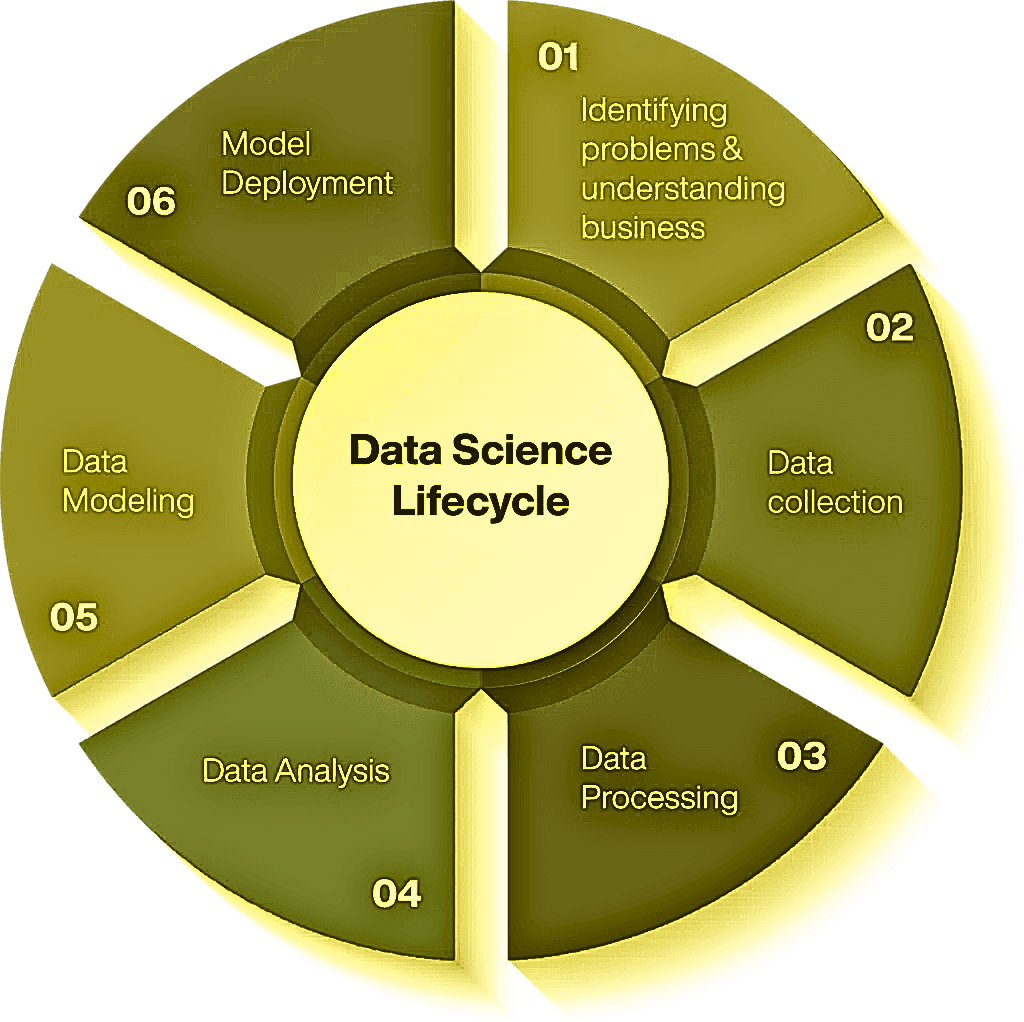
Identify the problem and understand the business.
- Like any good business lifecycle, the data science lifecycle revolves around the question “why?” Starts with. Identifying the problem is one of the essential steps in the data science process, which allows you to find a clear goal on which all subsequent steps can be built. In other words, it is important to understand your business goals from the beginning because they determine the ultimate goal of your analysis.
- This stage requires researching business trends, analyzing case studies for similar analysis, and researching industry sectors. The team assesses internal resources, infrastructure, total time and technology requirements. After identifying and evaluating all these aspects, formulate an initial hypothesis to solve the business problem as per the current scenario. steps must be:
- Clearly state the problem that needs solving and why it needs to be solved immediately.
- Define the potential value of your business project.
- Explore the risks, including ethical aspects, involved in the project.
- Create and communicate highly integrated and flexible project plans.
- Data collection
- Data collection is the next step in the data science lifecycle that collects raw data from relevant sources. The captured data can be in structured or unstructured format. Data collection methods include logs from websites, social media data, data from online repositories, and even streaming from online sources via APIs, web scraping, or data present in Excel or other sources.
- Functionaries must understand the differences between the different datasets available and the organization’s data investment strategy. A major challenge faced by experts at this stage is to track where each piece of data comes from and whether it is up-to-date. It is important to track this information throughout the lifecycle of your data science project, as it can be useful for testing hypotheses and conducting other updated experiments.
- Information processing
- During this phase, data scientists analyze the collected data to look for biases, patterns, categories, and distribution of values. This is done to determine the stability of the database and predict its use in regression, machine learning, and deep learning algorithms. This stage also includes introspection of different types of data, such as nominal, numerical and categorical data.
- Data visualization is also used to highlight important trends and patterns in the data and are captured in simple bar and line graphs. Simply put, data processing is the most time-consuming phase of the entire data analysis lifecycle, but perhaps also the most important. The quality of the model depends on this data processing step.
Data analysis
Data analysis or exploratory data analysis is another important step to get ideas about solutions and factors influencing the data science lifecycle. There are no set guidelines and no shortcuts in this method. The important thing to remember here is that input determines output. In this section, we explore the data prepared in the previous step to explore various features and their relationships to improve the selection of features required to be applied to the model.
Experts use data statistical techniques like average and median to understand the data better. Additionally, plot the data and evaluate its distribution patterns using histograms, spectral analysis, and population distributions. The data is analyzed according to the problem.
Data modeling
Data modeling is one of the key steps in data processing and is often referred to as the heart of data analysis. The model must use data prepared and analyzed to provide the required output. The environment required to run the data model is determined and built in advance to meet your specific requirements.
During this phase, the team works together to develop datasets on which to train and test models for production purposes. It also requires various tasks, such as choosing the appropriate mode type and learning whether the problem is a classification, regression, or clustering problem. After analyzing model families, you need to choose algorithms to implement them. Extracting the necessary insights from the generated data is important and should be done carefully.
Open the model
We are currently in the final stages of the data science lifecycle. After a rigorous evaluation process, the model is finally ready for deployment in the desired format and preferred channel. Remember that machine learning models have no value until they are deployed in production. Therefore, machine learning models should be recorded before the deployment process. These models are usually integrated and coupled with products and applications.
The model deployment phase involves creating the necessary distribution mechanisms to market the model among users or provide it to another system. Machine learning models are also being deployed on devices, being adopted in computing and gaining popularity. From simple model output in a Tableau dashboard to complex models scaling to the cloud in front of millions of users, this step will vary for each project.
Carrier in the data science lifecycle
Data is created, collected and stored in servers and data stores on a large scale, from personal to organizational level. But how do you get access to this vast amount of data storage? This is where data scientists come in handy. Data scientists are experts in the art of extracting insights and patterns from unstructured words and numbers.
Here, we have listed various job profiles for data science teams involved in the data science lifecycle.
Business Analyst
The role of a business analyst is to understand the business needs in a specific sector, such as banking, healthcare or education.
They can guide you in planning the right solution and timeline for performing analytics across the business analytics lifecycle. You also need to find the right target customers, analyze the effectiveness of various campaigns, create plans, and facilitate business processes.
Data Analyst
Data analysts are data science professionals who have extensive knowledge and experience working with large amounts of data. You can map out your solution and analyze what data is needed to generate the solution you need. Data analysts must format and clean raw data, interpret and visualize it to perform analysis, and provide a technical overview of it.
Data scientist
Data scientists are a step forward in the data science lifecycle and their primary job is to improve the quality of machine learning models. Generally, they divide their work into two sections.
- Continuously assess quality using the full project model to identify areas for improvement.
- Collect online and offline metrics to find signals for new architectures and predictions.
Data Engineer
Data engineers focus on optimizing techniques and creating data using traditional methods. They are responsible for preparing data collected from social networks, websites, blogs and other internal and external web sources for subsequent analysis. It is then created in a structured format and can be shared with data analysts for further steps.
Data Architect
The primary role of a data architect is to integrate, centralize, secure, and maintain data sources throughout an organization’s lifecycle. To stay on top of your business and remain relevant, you need to take advantage of the latest technology. Furthermore, data architects have an important role in creating the blueprint for database management and organizing data at both macro and micro levels.
Machine Learning Engineer
The job profile of a Machine Learning Engineer includes the responsibility of advising on what models can be applied to achieve the desired results and how to create solutions that provide accurate outputs. Machine learning-related algorithms and applications, such as prediction and anomaly detection, need to be designed and implemented to solve business challenges. They work together to create data pipelines, benchmarking infrastructure, and A/B testing.
You should know more about Artificial Intelligence
- Machine Learning in Computer Vision
- Top 10 Machine Learning Application and examples to know in 2024
- Goals of artificial intelligence: 8 major types, AI definitions and application
- What are artificial neural networks? Types and Applications in AI
- 7 Best AI Video Generators 2024
- Differences between Machine Learning and Artificial Intelligence: 4 types, Applications and examples
- Top 10 Best AI Image Generator Tools 2024 (Free and Paid)
- 10 AI Robotics Companies: Innovation of Driving
follow me : Twitter, Facebook, LinkedIn, Instagram