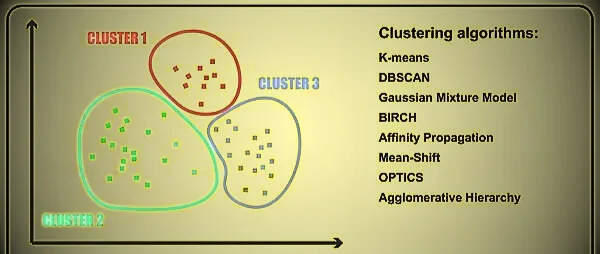
Clustering in Machine Learning
In the real world, not all the data we work with has a target variable. This type of data cannot be analyzed using supervised learning algorithms. We need the help of untrained algorithms. One of the most common types of analysis in unsupervised learning is cluster analysis. Use cluster analysis when your goal is to group similar data points in a dataset. In real-world situations, cluster analysis can be used for customer segmentation for targeted advertising, medical image processing to find unknown or newly infected areas, and much more, which is covered in this article. Will be discussed in more detail in examples of use.
What is clustering in machine learning?
The act of grouping data points based on their similarity to each other is called clustering or cluster analysis. This method is defined in the unsupervised learning branch and aims to gain insights from unlabeled data points. That is, unlike supervised learning, there is no target variable.
The purpose of clustering is to create groups of homogeneous data points from a heterogeneous dataset. Evaluate similarity based on metrics such as Euclidean distance, cosine similarity, and Manhattan distance, and group points with the highest similarity scores.
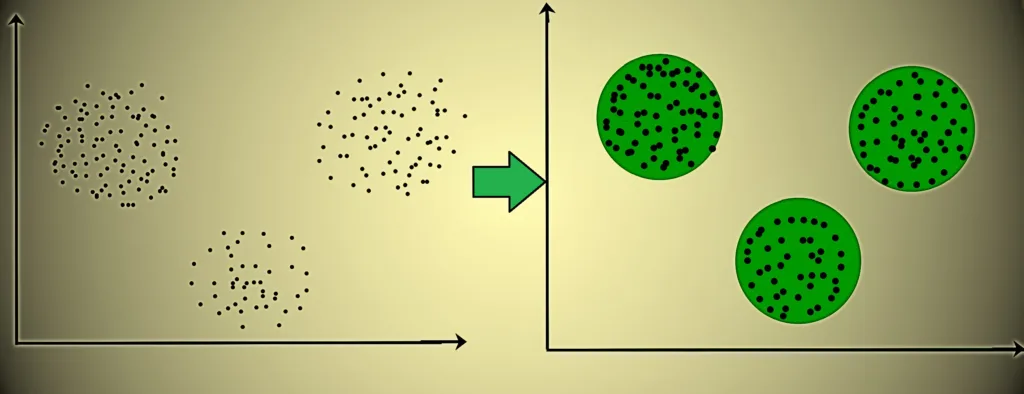
For example, in the graph given below, we can clearly see that there are 3 circular clusters forming on the basis of distance.
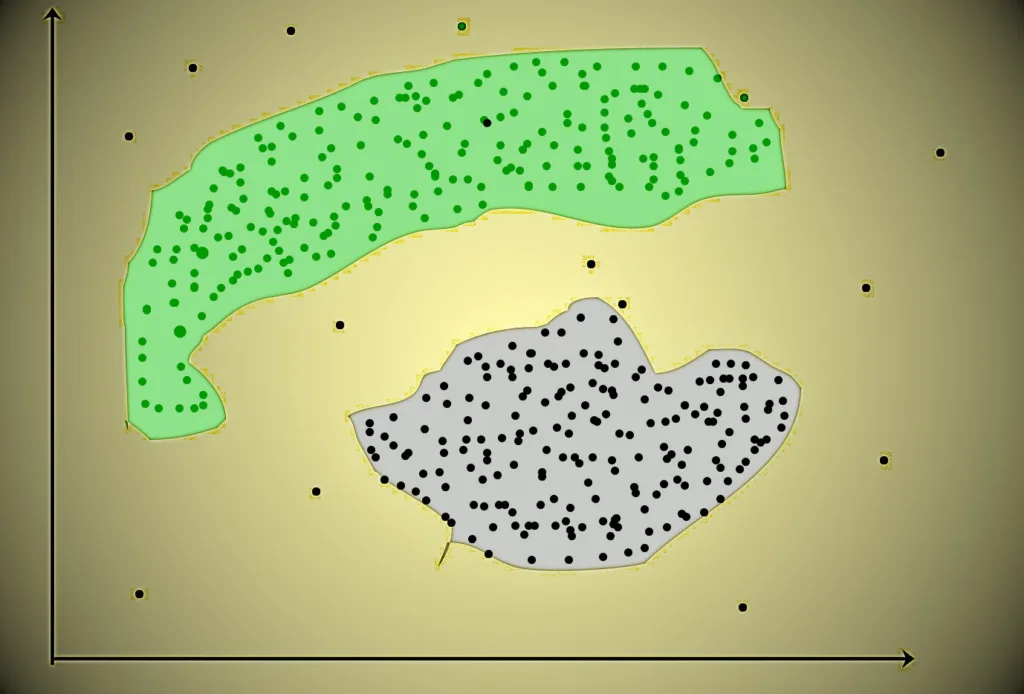
The shape of the clusters formed here is not necessarily circular. The size of the cluster is arbitrary. There are many algorithms suitable for detecting clusters of arbitrary shapes.
For example, in the graph below, you can see that the clusters formed are not circular in shape.
The shape of the clusters formed here is necessarily circular. The size of the cluster is arbitrary. There are many algorithms suitable for detecting clusters of arbitrary shapes.
For example, in the graph below, you can see that the clusters formed are not circular in shape.
importance of clustering
Clustering is sometimes also called unsupervised machine learning. To perform clustering, you usually do not need labels for known previous outcomes (dependent variable, y variable, target variable, or labeled variable). For example, if you apply clustering techniques to the mortgage application process, you do not need to know whether the applicant has paid a mortgage in the past. Rather, it requires demographic, psychographic, behavioral, geographic, or other information about applicants to a mortgage portfolio. Clustering techniques attempt to group applicants based on that information. This method contrasts with supervised learning, which can predict a new applicant’s mortgage default risk, for example, based on patterns in data labeled with past default outcomes.
Clustering generally groups input data together, making it very creative and flexible. Clustering can be used not only for data exploration and preprocessing but also for specific applications. From a technical perspective, common applications of clustering include:
- Data visualization. Data often have natural groups and segments, and clustering needs to be able to find them. Cluster visualization can be a very useful data analysis approach.
- Prototype. A prototype is a data point that represents many other points and helps explain your data and model. If a cluster represents a larger market segment, the data point at the center of the cluster (or cluster centroid) is a typical member of that market segment.
- Sampling. Because clustering allows you to define groups in your data, you can use clusters to create different types of data samples. For example, removing an equal number of data points from each cluster in a data set creates a balanced sample of the population represented by that data set.
- Model section. The predictive performance of supervised models (such as regression, decision trees and neural networks) can sometimes be improved by using information learned from unsupervised approaches such as clustering. Data scientists can incorporate clusters as inputs into other models or create separate models for each cluster.
For business applications, clustering is a proven tool for market segmentation and fraud detection. Clustering is also useful for classifying documents, making product recommendations, and other applications where it makes sense to group entities.
Types of Clustering in machine learning
Broadly speaking, there are two types of clustering that can be done to group similar data points.
- Hard Clustering: In this type of clustering, each data point belongs to a cluster, regardless of whether it completely belongs to the cluster or not. For example, let’s say you have four data points and need to cluster them into two groups. Therefore, each data point belongs to either Cluster 1 or Cluster 2.
| Data Points | Clusters |
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Soft clustering: In this type of clustering, instead of assigning each data point to a separate cluster, the likelihood or probability of the point being in that cluster is evaluated. For example, let’s say you have four data points and need to cluster them into two groups. Therefore, we evaluate the probability of a data point belonging to both groups. This probability is calculated for each data point.
| Data Points | Probability of C1 | Probability of C2 |
| A | 0.91 | 0.09 |
| B | 0.3 | 0.7 |
| C | 0.17 | 0.83 |
| D | 1 | 0 |
Uses of Clustering in machine learning
Before discussing the types of clustering algorithms, let’s discuss some examples of how they can be used. Clustering algorithms are mainly used for:
- Market segmentation: Business groups use clustering to target customers and targeted advertising to attract larger audiences.
- Market Basket Analysis: Store owners analyze sales to understand which products customers primarily buy together. For example, in the United States, a study found that diapers and beer are commonly purchased together by fathers.
- Social network analytics: social media sites use your data to understand your browsing behavior and provide targeted friend and content recommendations.
- Medical images: Doctors use clustering to detect areas of disease in clinical images such as X-rays.
- Anomaly detection: Use clustering to identify outliers in a stream of real-time datasets or predict fraudulent transactions.
- Simplify working with large datasets. Once clustering is complete, each cluster is given a cluster ID. Now you can collapse your entire feature set to that cluster ID. Clustering is effective when complex cases can be represented by simple cluster IDs. Using the same principle, clustering data can simplify complex datasets.
Although there are many other use cases for clustering, there are some primary and common use cases for clustering. In the future, we will discuss clustering algorithms that will help you perform the above task.
Types of clustering algorithms
There are many types of clustering algorithms, but the most widely available in data science tools are k-means and hierarchical clustering.
K-means clustering
The K-means clustering algorithm chooses a certain number of clusters to form in the data, denoted by k. K can be 3, 10, 1,000, or any other number of clusters, but lower numbers are better. The algorithm then creates k clusters, and the center point, or centroid, of each cluster is the average value of each variable in the cluster. K-means and related approaches, such as k-mediation for character data and k-prototype for mixed numeric and character data, are fast and perform well on large data sets. However, generally, you want to create simple spherical clusters of approximately equal size.
Hierarchical clustering
If you are looking for more complex and realistic clusters of different shapes and sizes and do not want to choose k before starting the analysis, hierarchical clustering may be a better choice. Hierarchical clustering corresponds to a partitioning approach. That is, start with a large cluster, divide it into smaller clusters until each point has its own cluster, and then choose among all the interesting clustering solutions in between.
Another option is the collective approach, where each data point starts in its own cluster. Combine the data points into clusters until all the points form a large cluster, and select the best cluster among them. Unfortunately, hierarchical clustering algorithms are slow or impossible for big data, so you need to choose k to arrive at the final answer.
One of the hardest parts of clustering is choosing the optimal number of clusters for your data and application. There are data-driven methods to estimate K, such as silhouette scores and gap statistics. These quantitative formulas provide numerical scores that help you choose the optimal number of groups. Domain knowledge is also available. For example, your project may have enough budget for 10 different marketing campaigns, so business concerns may dictate that 10 is the appropriate number of groups, or you may be an experienced marketer who has been working with a company for a long time. The optimum number of years has worked in the particular industry. of the segment for the market. Combining quantitative analysis with domain knowledge also often works well.
At a superficial level, clustering helps analyze unstructured data. Graphing, minimum distance and density of data points are some of the factors that influence cluster formation. Clustering is the process of determining how related objects are based on a metric called a similarity measure. Similarity metrics are easy to find when the set of features is small. As the number of features increases, creating a similarity measure becomes more difficult. Depending on the type of clustering algorithm used in data mining, several techniques are used to group data from a dataset. This section describes clustering techniques. There are different types of clustering algorithms:
- Centroid-based Clustering (Partitioning methods)
- Density-based Clustering (Model-based methods)
- Connectivity-based Clustering (Hierarchical clustering)
- Distribution-based Clustering
We will be going through each of these types in brief.
1. Centroid-based clustering (partition method)
Partitioning techniques are the simplest clustering algorithms. Data points are grouped based on their proximity. Typically, the similarity measures chosen for these algorithms are Euclidean distance, Manhattan distance, or Minkowski distance. The dataset is divided into a predetermined number of clusters, and each cluster is referred to by a vector of values. When vector values are compared, there is no difference in the input data variables and they participate in the cluster.
The main drawback of these algorithms is that the number of clusters “k” must be established intuitively or scientifically (using the elbow method) before the clustering machine learning system starts assigning data points. Nevertheless, it is still the most popular type of clustering. K-means clustering and k-medoids clustering are examples of this type of clustering.
2. Density-Based Clustering (Model-Based Method)
Density-based clustering, a model-based method, finds groups based on the density of data points. Unlike centroid-based clustering, which requires the number of clusters to be defined in advance and is sensitive to initialization, density-based clustering automatically determines the number of clusters and is less sensitive to the initial condition of the mass. Is sensitive. They are excellent at handling clusters of varying sizes and formats, making them ideal for datasets with irregular shapes or overlapping clusters. These methods can focus on local density, handle both dense and sparse data regions, and distinguish between different forms of clusters.
In contrast, centroid-based clustering such as K-means has difficulty finding clusters of arbitrary size. Results may vary due to the high sensitivity of the number of preset cluster requirements and the initial location of the centroid. Additionally, centroid-based approaches produce spherical or convex clusters, which limits their ability to handle complex or irregularly shaped clusters. In conclusion, density-based clustering overcomes the shortcomings of centroid-based methods by autonomously selecting the cluster size, being flexible for initialization, and successfully capturing clusters of different sizes and formats. The most common density-based clustering algorithm is DBSCAN.
3. Connection-Based Clustering (Hierarchical Clustering)
The method of aggregating related data points into hierarchical groups is called hierarchical clustering. Each data point is initially treated as a separate cluster and then combined with the most similar clusters to form a larger cluster containing all the data points.
Think about how to organize your collection of items based on their similarities. With hierarchical clustering, each object starts as its own cluster at the root of the tree, forming a dendrogram (tree-like structure). The algorithm combines the closest pairs of clusters into a larger cluster after seeing how similar the objects are to each other. The merge process is complete when all objects fit into a cluster at the top of the tree. Exploring different levels of granularity is part of the fun of hierarchical clustering. To get a specific number of clusters, you can choose to cut the dendrogram at a specific height. The more similar two objects in a cluster are, the closer they are. This is similar to classifying things according to the family tree. In a family tree, the closest relatives are grouped together, with wider branches indicating more common connections. There are two approaches to hierarchical clustering.
- Partitioned clustering follows the top-down approach. We consider all data points as part of a larger cluster and then divide this cluster into smaller clusters.
- Agglomerative clustering follows the bottom up approach. Here, we consider all data points as parts of different clusters. These clusters are then combined to form a larger cluster that contains all the data points.
4. Distribution-Based Clustering
Distribution-based clustering generates and arranges data points according to trends in the data that fall under the same probability distribution (such as Gaussian or binomial). Data elements are grouped using a probability-based distribution based on statistical distributions. This includes data objects that are likely to exist within the cluster. The farther a data point is from the cluster center point, which is present in all clusters, the less likely it is to be in the cluster.
A notable drawback of density- and threshold-based approaches is that they require clusters to be specified in advance for some algorithms and cluster forms to be defined primarily for most algorithms. At least one adjustment or hyperparameter, must be selected. This should be easy, but getting it wrong can have unintended consequences. Distribution-based clustering has distinct advantages over proximity-based and centroid-based clustering approaches in terms of flexibility, accuracy, and cluster structure. A major issue is that, to avoid overfitting, many clustering methods only work on simulated or constructed data, or when a large portion of the data points reliably belong to a predetermined distribution. The most common distribution-based clustering algorithm is the Gaussian mixture model.
Applications of Clustering in various fields:
- Marketing: This can be used to characterize and find customer segments for marketing purposes.
- Biology: It can be used to classify different types of plants and animals.
- Library: Used to group different books based on subject and information.
- Insurance: Used to verify customers and their insurance policies and identify fraudulent activity.
- Urban planning is used to create groups of dwellings and study their value based on geographical location and other factors present.
- Earthquake Research: Knowing the areas affected by earthquakes allows us to determine danger areas.
- Image Processing: Clustering can be used to group similar images, classify images based on content, and identify patterns in image data.
- Genetics: Clustering is used to group genes with similar expression patterns and identify gene networks that work together in biological processes.
- Finance: Clustering is used to identify market segments based on customer behavior, identify patterns in stock market data, and analyze risk in investment portfolios.
- Customer Service: Clustering is used to group customer inquiries and complaints into categories, identify common problems, and develop targeted solutions.
- Manufacturing: Clustering is used to group similar products, optimize production processes, and identify defects in manufacturing processes.
- Medical diagnosis: Clustering is used to group patients with similar symptoms or diseases to help identify accurate diagnoses and effective treatments.
- Fraud detection: Clustering is used to identify suspicious patterns and anomalies in financial transactions, which helps in detecting fraud and other financial crimes.
- Traffic analysis: Clustering is used to group traffic data with similar patterns, such as peak hours, routes, and speeds, to help improve transportation planning and infrastructure.
- Social Network Analysis: Clustering is used to identify communities and groups within social networks, helping to understand social behavior, influence, and trends.
- Cyber Security: Clustering is used to group similar patterns of network traffic or system behavior to help detect and prevent cyber attacks.
- Climate Analysis: Clustering is used to group climate data with similar patterns, such as temperature, precipitation, and wind, to help understand climate change and its impact on the environment.
- Sports Analytics: Clustering is used to group similar patterns in player or team performance data. This helps you analyze the strengths and weaknesses of a player or team and make strategic decisions.
- Crime Analysis: Clustering is used to group similar patterns in crime data, such as location, time, type, etc. This helps in identifying crime hotspots, predicting future crime trends and improving crime prevention strategies.
Conclusion
Although clustering is a very useful machine-learning technique, it is not as simple as supervised learning, which uses cases like classification and regression. The main reason is that performance evaluation and model quality assessment are difficult and there are some important parameters, such as the number of clusters, that need to be correctly defined by the user to get meaningful results.
Frequently Asked Questions (FAQs) on Clustering in machine learning
What are the best clustering method and algorithms?
The top 10 clustering algorithms are:
- K-means Clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussian Mixture Models (GMM)
- Agglomerative Clustering
- Spectral Clustering
- Mean Shift Clustering
- Affinity Propagation
- OPTICS (Ordering Points To Identify the Clustering Structure)
- Birch (Balanced Iterative reduction and Clustering using Hierarchies)
What is the main purpose of clustering?
Clustering is used to identify groups of similar objects in datasets with two or more variable quantities.
What is the difference between clustering and classification?
The main difference between clustering and classification is that classification is a supervised learning algorithm, whereas clustering is an unsupervised learning algorithm. That is, apply clustering to the dataset without the target variable.
What are the advantages of clustering analysis?
Cluster analysis is a powerful analytical tool that allows you to organize your data into meaningful groups. You can use it to pinpoint segments, find hidden patterns, and improve decision-making.
Which is the fastest clustering method?
K-means clustering is considered to be the fastest clustering method due to its simplicity and computational efficiency. It iteratively assigns data points to the nearest cluster centroid, making it suitable for large datasets with low dimensionality and a moderate number of clusters.
What are the limitations of clustering?
Limitations of clustering include sensitivity to initial conditions, dependence on parameter selection, difficulty in determining the optimal number of clusters, and challenges in handling high-dimensional or noisy data.
What does the quality of the result of clustering depend on?
The quality of clustering results depends on factors such as algorithm selection, distance metric, number of clusters, initialization method, data preprocessing techniques, cluster evaluation metrics, and domain knowledge. Collectively, these factors affect the effectiveness and accuracy of clustering results.
follow me : Twitter, Facebook, LinkedIn, Instagram
1 thought on “Clustering in Machine Learning: 5 essential algorithms you should know about”
Comments are closed.