What is machine learning algorithms?
Machine learning algorithms are computational models that allow computers to understand patterns and make predictions or decisions based on data without the need for explicit programming. These algorithms form the basis of modern artificial intelligence and are used in a wide range of applications, including image and speech recognition, natural language processing, recommendation systems, fraud detection, self-driving cars, and much more.
This machine learning algorithms article covers vector machines, decision making, logistics regression, naive Bayes classifiers, random forests, k-means clustering, reinforcement learning, vectors, hierarchical clustering, XGBoost, Adaboost, logistics, etc.
What is machine learning? You should know about
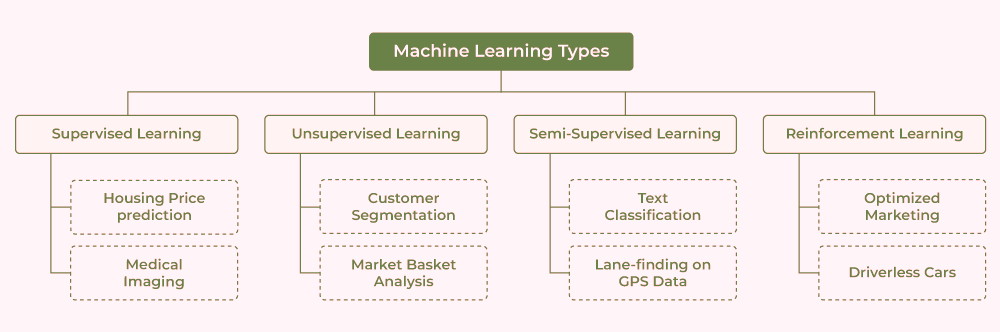
Types of Machine Learning Algorithms
Machine learning algorithms specify the rules and processes that a system should consider when solving a particular problem. These algorithms analyze and simulate data to predict outcomes within a given range. Additionally, as new data is fed into these algorithms, they learn, adapt, and improve based on feedback from past performance in predicting outcomes. Simply put, machine learning algorithms become “smarter” with each iteration.
Depending on the type of algorithm, machine learning models use many parameters, like the gamma parameter, max_Depth, n_neighbors, etc., to analyze the data and deliver accurate results. These parameters are the result of training data that represents a large dataset.
Machine learning algorithms are classified into four types based on the method of learning:
- Supervised learning,
- Semi-supervised learning,
- Unsupervised learning and
- Reinforcement learning.
Regression and classification algorithms are the most popular choices for predicting values, identifying similarities, and discovering unusual data patterns.
Let’s briefly discuss the machine learning algorithms
There are three types of machine learning algorithms.
- Supervised Learning
- Regression
- Classification
- Unsupervised Learning
- Clustering
- Dimensionality Reduction
- Reinforcement Learning
Supervised learning
Supervised learning algorithms use labeled datasets to make predictions. This learning technique is useful if you know what type of result or outcome you are trying to achieve.
Unsupervised learning
Unsupervised learning algorithms use unlabeled data. This learning method labels unlabeled data by classifying or representing its type, format, and structure. This technique is useful when the type of result is unknown.
Reinforcement Learning
Reinforcement learning is a type of machine learning algorithm in which an agent learns to make decisions continuously by interacting with its environment. Agents receive feedback in the form of incentives or punishments, depending on their actions. The agent’s objective is to discover the optimal strategy that maximizes cumulative rewards over time through trial and error. Reinforcement learning is often used in scenarios where an agent needs to learn how to navigate an environment, play a game, manage a robot, or make decisions under uncertain circumstances.
Reinforcement learning algorithms use the results or outcomes as a benchmark to determine the next action step. In other words, these algorithms learn from previous results, receive feedback after each step, and decide whether Bernoulli should proceed to the next step. Along the way, the system learns whether it has chosen the right option, the wrong option, or a neutral option. Automated systems are designed to make decisions with minimal human intervention, so they employ reinforcement learning.
For example, let’s say you want to design a self-driving car and track whether it follows traffic rules and stays safe on the road. By implementing reinforcement learning, vehicles learn through experience and reinforcement strategies. This algorithm ensures that the car follows traffic laws such as staying in one lane, respecting speed limits, and avoiding encounters with pedestrians and animals on the road.
Know more about Reinforcement Learning
Semi-supervised learning (SSL)
Semi-supervised learning algorithms are a combination of both of the above, using labeled and unlabeled data. The purpose of these algorithms is to classify unlabeled data based on information obtained from labeled data.
Consider the example of web content classification. Sorting and categorizing the content available on the Internet is a time- and resource-intensive task. In addition to AI algorithms, human resources are required to organize the billions of web pages available online. In such cases, the SSL model can play a vital role in getting the job done efficiently.
10 Popular Machine Learning Algorithms?
Below is the list of Top 10 commonly used Machine Learning (ML) Algorithms:
Linear regression
Linear regression shows the relationship between an input variable (x) and an output variable (y). It is also called independent variable or a dependent variable. Let us understand the algorithm using an example where several plastic boxes of different sizes need to be placed on different shelves depending on their respective weights.
This task must be accomplished without manually weighing the boxes. Instead, you just have to estimate the weight by looking at the height, dimensions, and shape of the box. This means that the entire work is driven by visual analysis. Therefore, the variables shown must be used in combination to reach the final position on the shelf.
Linear regression is a similar type in machine learning, where the relationship between independent and dependent variables is established by fitting them to a regression line. The mathematical representation of this line is given by the linear equation y = mx + c. Where y represents the dependent variable, m = slope, x = independent variable, and b = intercept.
The goal of linear regression is to find the best straight line that describes the relationship between the variables y and x.
Logistic regression
Logistic regression is an extension of linear regression that is used for classification tasks to estimate the probability that an example belongs to a particular class.
In logistic regression, the dependent variable is binary. This type of regression analysis describes data and explains the relationship between a dichotomous variable and one or more independent variables.
Logistic regression is used in predictive analysis, where data are related to a logit function to predict event probabilities. Therefore, it is also called logit regression.
Mathematically, logistic regression is represented by the equation:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Here,
x = input value, y = predicted output, b0 = bias or intercept term, b1 = coefficient for input (x).
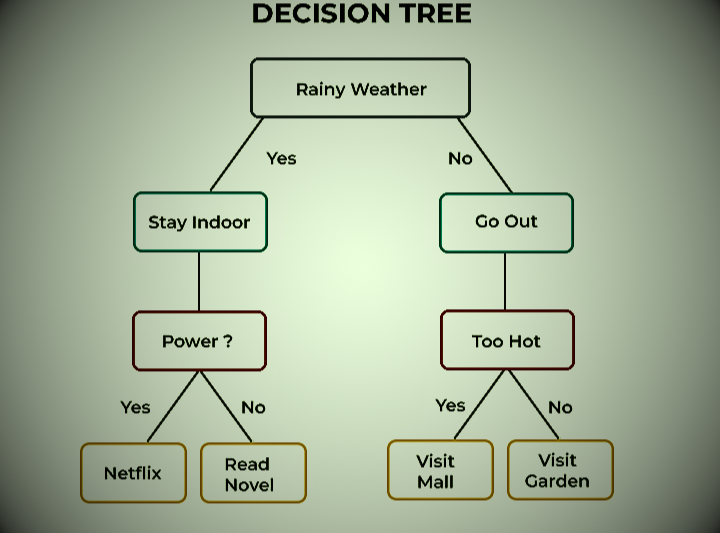
Decision tree
Decision trees are a type of supervised learning technique that can be used for classification and regression. It works by dividing data into smaller and smaller groups until each group can be classified or predicted with high accuracy.
Decision tree algorithms can potentially predict the best option based on their mathematical structure and are also useful when brainstorming a particular decision. The tree starts from a root node (decision node) and branches into subnodes representing possible outcomes.
Each result allows you to create more child nodes, which can open up other possibilities. This algorithm produces a tree-like structure that is used for classification problems. For example, consider the decision tree below that helps you finalize your weekend plans based on the weather forecast.
Support Vector Machine (SVM) algorithm
SVM is a supervised learning algorithm that can perform classification and regression tasks. Find the hyperplane that best separates classes in the feature space.
Support vector machine algorithms are used to perform both classification and regression tasks. These are supervised machine learning algorithms that plot each piece of data in an n-dimensional space (n refers to the number of features). Each feature value is associated with a coordinate value, making it easy to plot features.
Naive Bayes algorithm
Naive Bayes refers to a probabilistic machine learning algorithm based on Bayesian probabilistic models that is used to address classification problems. The basic assumption of this algorithm is that the features under consideration are independent of each other and changing the value of one has no effect on the value of the other.
Naive Bayes is a probabilistic classifier based on Bayes’ theorem used for classification tasks. It works by assuming that the characteristics of the data points are independent of each other.
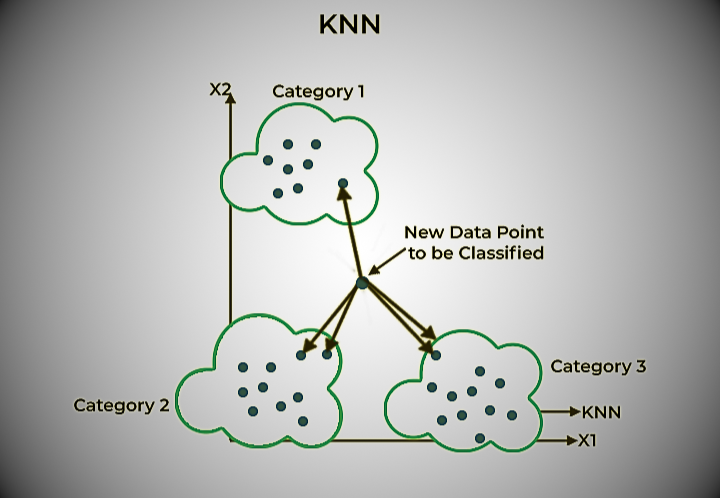
K-nearest neighbor (KNN) classification algorithm
KNN is a non-parametric method that can be used for classification and regression. It works by identifying the data points most similar to a new data point and using the labels of those data points to predict the label of the new data point.
The K-Nearest Neighbors (KNN) algorithm is used for both classification and regression problems. Save all known use cases and separate and classify new use cases (or data points) into different classes. This classification is based on the similarity score of recent use cases and available use cases.
KNN is a supervised machine learning algorithm, where “k” refers to the number of neighbors considered when classifying and separating known N clusters. The algorithm learns with each step and iteration, eliminating the need for a specific learning step. Classification is based on a majority vote of neighborhood residents.
The algorithm uses the following steps to perform classification:.
- For the training dataset, calculate the distance between the data point being classified and the remaining data points.
- Select the nearest ‘K’ elements based on the distance or function used.
- Consider “majority voting” among k points. The class or label that dominates all the data points provides the final ranking.
K-means
K-means clustering is an unsupervised learning approach that can be used to group data points. It works by finding k clusters in the data so that the data points in each cluster are as similar to each other and as different as possible from the data points in other clusters.
K-means clusters are created using the following steps:.
- Initialization: The k-means algorithm selects the centroid (“k”) points of each cluster.
- Assign objects to centroids: For each data point, the nearest centroids (K clusters) form a cluster.
- Update centroid: Creates a new centroid based on the existing cluster and determines the closest distance to each data point based on the new centroid. Here, the location of the center of mass is also updated if necessary.
- Repeat: Repeat the process until the center of gravity changes.
Random forest algorithm
Random forest is a type of ensemble learning method that uses a set of decision trees to make predictions by aggregating predictions from individual trees. Improves the accuracy and flexibility of a single decision tree. It can be used for both classification and regression tasks.
PCA (Principal Component Analysis)
PCA is a dimensionality reduction technique used to transform data into a lower-dimensional space while preserving as much variation as possible. It works by finding the direction in the data that has the most variation and interpolating the data in that direction.
Apriori algorithms
The apriori algorithm is a traditional data mining technique for association rule mining in transactional databases or datasets. It is designed to reveal links and patterns between things that occur together regularly in transactions. Apriori detects frequent itemsets, which are groups of items that appear together in transactions with a given minimum support level.
Here are interesting topics about artificial intelligence that you did not know
- Artificial intelligence: Definition Applications, types, and examples
- What is artificial intelligence? types of AI, courses and top 10 companies
- What is natural language processing?
- Big Exploration of Machine Learning: Exclusive Definition, Types, and Applications in 2024
- Top 10 Machine Learning Application and examples to know in 2024
- Machine Learning in Computer Vision
- Clustering in Machine Learning: 5 essential algorithms you should know about
- What is natural language processing?
follow me : Twitter, Facebook, LinkedIn, Instagram
1 thought on “what are Machine Learning Algorithms: The Complete 2025 Guide”
Comments are closed.