Large language models (LLM) are a breakthrough in artificial intelligence that employ neural network technology with a wide range of parameters for advanced language processing.
This article explores the development, architecture, applications, and challenges of LLM, focusing on its impact on the field of natural language processing (NLP).
What is large language model (LLM)?
Large language models are a type of artificial intelligence algorithm that applies neural network techniques with multiple parameters to process and understand human language and text using self-supervised learning techniques. Tasks such as text generation, machine translation, summarization, image generation from text, machine coding, chatbots, and conversational AI are large applications of language models. Examples of such LLM models include Chat GPT by Open AI and BERT (Bidirectional Encoder Representations from Transformers) by Google.
Although there are many techniques that have been attempted to perform natural language-related tasks, LLM is based entirely on deep learning methods. LLM (large language models) models can very efficiently capture complex entity relationships in existing text and generate text using the semantics and syntax of the specific language of interest.
Large language models primarily represent a class of deep learning architectures called transformer networks. Transformer models are neural networks that learn context and meaning by tracking relationships in continuous data, like the words in this sentence.
A transformer consists of several transformer blocks, also called layers. For example, a transformer has a self-attention layer, a feedforward layer, and a normalization layer that work together to decode the input and predict the output stream during inference. Stack layers to create deeper transformers and more powerful language models.
There are two important innovations that make Transformer particularly suitable for large language models. This is positional encoding and self-attention.
Positional encoding embeds the order in which the input occurs within a given sequence. Essentially, instead of feeding the words in a sentence sequentially into a neural network, positional encoding allows us to feed them non-sequentially.
Self-attention assigns importance to each piece of input data when processing it. This weight indicates the importance of that input relative to the rest of the inputs in the context. In other words, the model no longer needs to pay equal attention to all inputs and can focus on the parts of the input that really matter. This representation of which parts of the input the neural network should pay attention to is learned over time as the model sifts through and analyzes mountains of data.
Together, these two techniques allow us to analyze the subtle ways and contexts in which different elements interact and interact continuously over long distances.
Data can be processed non-sequentially, allowing complex problems to be broken down into many smaller calculations performed simultaneously. Naturally, GPUs are well suited to solving these types of problems in parallel, allowing the processing of large-scale unlabeled datasets and huge transformation networks.
Large Language Models in GPT
Just talking about the magnitude of progress in GPT (Generative Pre-trained Transformer) models:
- GPT-1, released in 2018, has 117 million parameters and contains 985 million words.
- GPT-2, released in 2019, contains 1.5 billion parameters.
- GPT-3, released in 2020, contains 175 billion parameters. Chat GPT is also based on this model.
- The GPT-4 model is expected to be released in 2023 and may include trillions of parameters.
How do Large Language Models work?
Large language models (LLM) work on deep learning principles and leverage neural network architectures to process and understand human language.
These models are trained on large-scale datasets using self-supervised learning techniques. The core of its functionality lies in the complex patterns and relationships that it learns from various linguistic data during training. LLM consists of several layers, such as the feedforward layer, embedding layer, and attention layer. These use attentional mechanisms such as self-attention to weigh the importance of different tokens in a sequence, allowing the model to capture dependencies and relationships.
Architecture of LLM
The architecture of a large language model (LLM) is determined by several factors, including the specific model design objective, available computational resources, and the type of language processing task performed by the LLM. The general architecture of LLM consists of several layers, such as the feedforward layer, embedding layer, and attention layer. The text embedded inside works together to generate the prediction.
Major components that influence the architecture of large language models are:
- Model size and number of parameters
- input expression
- Self-attention system
- Training objectives
- Computational efficiency
- Decoding and output generation
Transformer-Based LLM Model Architectures
Transformer-based models that have revolutionized natural language processing tasks typically follow a general architecture that includes the following components:
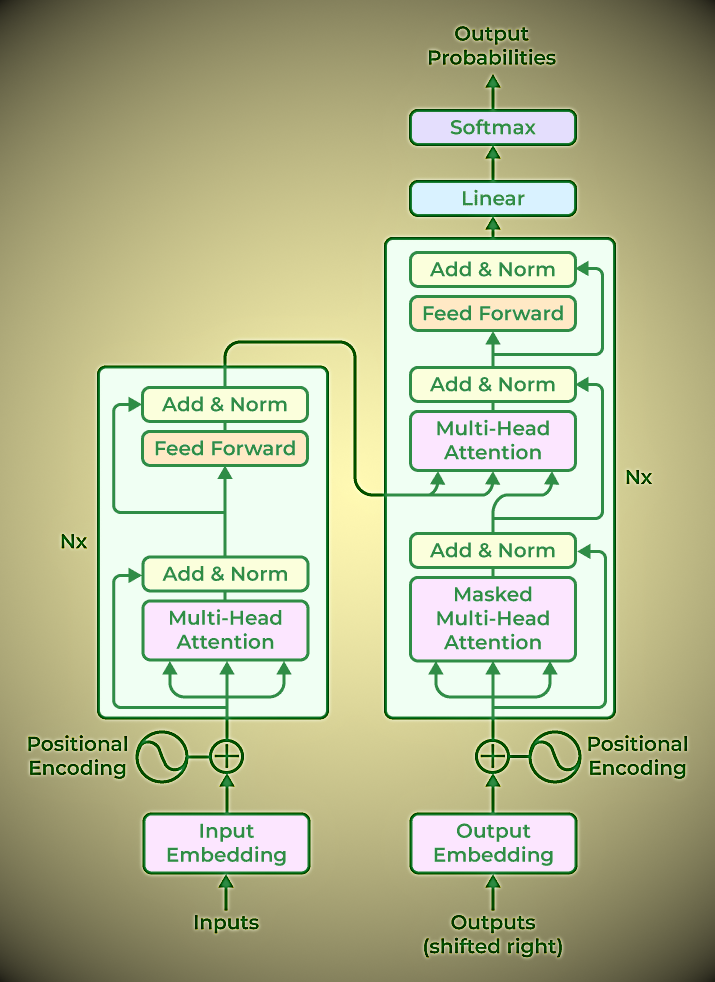
- Input embedding: The input text is tokenized into small units, such as words and subwords, and each token is embedded into a continuous vector representation. This embedding stage captures the semantic and syntactic information of the input.
- Positional encoding: Since Transformers do not inherently encode the order of tokens, a positional encoding is added to the input embedding to provide information about the position of the tokens. This allows the model to process tokens while respecting their order.
- Encoder: Based on neural network technology, the encoder analyzes the input text and creates a number of hidden states that protect the context and meaning of the text data. Multiple encoder layers form the core of the Transformer architecture. Self-attention mechanisms and feedforward neural networks are the two fundamental subcomponents of each encoder layer.
- Self-attention mechanism: Self-attention allows a model to weigh the importance of different tokens in the input sequence by calculating an attention score. This allows the model to consider dependencies and relationships between different tokens in a context-aware manner.
- Feedforward Neural Network: After the self-attention stage, a feedforward neural network is applied to each token individually. This network consists of fully connected layers with nonlinear activation functions, which allows the model to capture complex interactions between tokens.
- Decoder layer: Some transformer-based models include a decoder component in addition to the encoder. The decoder layer enables autoregressive generation, allowing the model to generate outputs sequentially by considering previously generated tokens.
- Multi-head attention: Transformers often use multi-head attention. In this case, self-attention is performed simultaneously with different learned attention weights. This allows the model to capture different types of relationships and process different parts of the input sequence simultaneously.
- Layer Normalization: Layer normalization is applied after each subcomponent or layer of the Transformer architecture. This stabilizes the learning process and improves the model’s ability to generalize to different inputs.
- Output Layer: The output layer of a transformer model varies depending on the specific task. For example, in language modeling, a linear interpolation followed by softmax activation is commonly used to generate a probability distribution for the next token.
It is important to note that the actual architecture of transformer-based models can be modified and extended based on specific research and model construction. Some models, such as GPT, BERT, and T5, can integrate more components and modifications to meet different tasks and purposes.
Large Language Models Examples
Let us now take a look at some of the famous LLMs that have been developed and argued.
- GPT-3: GPT stands for Generative Pretrained Transformer and is given the number 3 because it is the third version of such a model. It was developed by OpenAI, and you must have heard about Chat GPT. This is none other than the GPT-3 model launched by Open AI.
- BERT: Its full form is Bidirectional Encoder Representation Transformer. This large- language model was developed by Google and is commonly used for various tasks related to natural language. It can also be used to generate embeddings for specific text or to train other models.
- ROBERTA: Its full form is a robustly optimized BERT pre-training approach. Roberta is an improved version of the BERT model developed by Facebook AI Research, in a series of efforts to improve the performance of the Transformer architecture.
- Bloom: This is the first multilingual LLM created by a coalition of various organizations and researchers who have combined their expertise to develop this model similar to the GPT-3 architecture.
What can LLMs be used for?
LLM is powerful because it is generalizable to many different situations and applications. The same core LLM (possibly with some minor variations) can be used to perform dozens of different tasks. Everything they do is based on text generation, but the specific way in which they are asked to do so will affect their efficiency.
Here are some of the tasks for which LLMs are commonly used:
- General purpose chatbots (like ChatGPT and Google Bard)
- Customer service chatbots trained on business documents and data.
- Translate text from one language to another
- Convert text to computer code or convert one language into another
- Writing social media posts, blog posts and other marketing copy.
- sentiment analysis
- Content Moderation
- Correct and edit text.
- Data analysis
There are hundreds more. We are in the early stages of the current AI revolution.
However, there are many things that other types of AI models can do that LLMs cannot. some examples:
- Image interpretation
- Image creation
- Convert files between different formats
- Web Search
- Perform mathematical and other logical operations
Indeed, some LLMs and chatbots appear to perform some of these functions. But in most cases, another AI service steps in to help. If a model is processing many different types of input, it is no longer considered a true large language model, but is instead called a large-scale multimodal model (although to some extent this is just semantics. ).
With that context in mind, let’s move on to the LLM itself.
Top 12 LLMs Uses in Real Life
1. GPT
- Developer: OpenAI
- Parameters: More than 175 billion
- Access: AP
OpenAI’s Generative Pre-trained Transformer (GPT) model kicked off the latest AI hype cycle. There are currently two main models available: GPT-3.5-Turbo and GPT-4. GPT is a general-purpose LLM with an API that is used to power a myriad of different tools by companies like Microsoft, Duolingo, Stripe, Descriptor, Dropbox, Zapier, and countless others. Still, ChatGPT is probably the most popular demo of its capabilities.
You can also connect Zapier to GPT or ChatGPT, so you can use GPT directly from other apps in your tech stack. Here’s more information on how to automate ChatGPT. Or you can use one of these ready-made workflows to get started.
2. Gemini

- Developer: Google
- Parameters: Nano available in 1.8 billion and 3.25 billion versions; others unknown
- Access: API
Google Gemini is a family of AI models from Google. The three models, Gemini Nano, Gemini Pro and Gemini Ultra, are designed to work with a variety of devices, from smartphones to dedicated servers. While the Gemini model can generate text like an LLM, it can also natively process images, audio, video, code, and other types of information.
3. PaLM 2
- Developer: Google
- Parameters: 340 billion
- Access: API
PaLM 2 is Google’s LLM. Designed for natural language tasks, it powers most queries on Google Bard, as well as many of Google’s other AI features across apps, including Docs and Gmail. It is also available as an API for developers.
4. Llama 2
- Developer: Meta
- Parameters: 7 billion, 13 billion, and 70 billion
- Access: Open source
Llama2 is an open source LLM family from Meta, the parent company of Facebook and Instagram. It is one of the most popular and powerful open source LLMs, and you can download the source code yourself from Github. Many other LLMs use Llama 2 as a base, as it is free for research and commercial use.
5. Vicuna
- Developer: LMSYS Org
- Parameters: 7 billion, 13 billion, and 33 billion
- Access: Open source
Vicuna is an open-source chatbot built from Meta’s Llama LLM. It is widely used in AI research and as part of Chatbot Arena, a chatbot benchmark run by LMSYS.
6. Claude 2
- Developer: Anthropic
- Parameters: Unknown
- Access: API
Claude 2 is probably one of the most important competitors of GPT. It is useful to use for corporate clients and is designed to be honest, harmless and, importantly, safe to use. As a result, companies like Slack, Notion, and Zoom have partnered with Anthropic.
Like all proprietary LLMs, Cloud2 is only available as an API, but it can be further trained based on your data and fine-tuned to respond as needed. You can also connect the cloud to Zapier to automate the cloud from all your other apps. There are several pre-built workflows to get you started.
Stable Beluga and StableLM
- Developer: Stability AI
- Parameters: 7 billion, 13 billion, and 70 billion
- Access: Open source
Stability AI is the group behind Stable Diffusion, one of the best AI image generators. They have also released several open source LLMs based on Llama, such as Stable Beluga and StableLM, but they are not as popular as image generators.
7. Coral
- Developer: Cohere
- Parameters: Unknown
- Access: API
Like Cloud 2, Cohere’s Corel LLM is designed for enterprise users. It similarly offers an API that allows organizations to train versions of models based on their data, so they can accurately answer customer questions.
8. Falcon
- Developer: Technology Innovation Institute
- Parameters: 1.3 billion, 7.5 billion, 40 billion, and 180 billion
- Access: Open source
Falcon is an open source LLM family that performs consistently well on various AI benchmarks. It has models with up to 180 billion parameters and outperforms PaLM 2, Llama 2 and GPT-3.5 on some tasks. Released under the permissive Apache 2.0 license, it is suitable for commercial and research use.
9. MPT
- Developer: Mosaic
- Parameters: 7 billion, 30 billion
- Access: Open source
Mosaic’s MPT-7B and MPT-30B LLMs are two of the more powerful and popular LLMs on the market. Interestingly, unlike many other open source models, these are not built on top of Meta’s Llama model. The MPT-30B is an improvement over the original GPT-3 and, like the Falcon, is released under the Apache 2.0 license. There are several different versions available, modified for things like chatting, but the most interesting is the 7B version, which has been modified to produce longer forms of fiction.
10. Mixtral 8x7B
- Developer: Mistral
- Parameters: 46.7 billion
- Access: Open source
Mistral’s Mixtral 8x7B uses a series of sub-systems to efficiently defeat larger models. Performs better than Llama-70b and matches or exceeds GPT-3.5 despite having significantly lower parameters (so it can run on faster or less powerful hardware) I can. It is also released under the Apache 2.0 license.
11. XGen-7B
- Developer: Salesforce
- Parameters: 7 billion
- Access: Open source
Salesforce’s XGen-7B is not a particularly powerful or popular open source model. It performs almost the same as other open source models with 7 billion parameters. But I still think it’s worth including. This is to highlight how few large technology companies have AI and machine learning departments strong enough to develop and launch their own LLMs.
12. Grok
- Developer: xAI
- Parameters: Unknown
- Access: Chatbot
Grok, a chatbot trained on data from X (formerly Twitter), is not widely available or particularly good, so it doesn’t warrant a spot on this list on its own merits. Still, we list it here because it was developed by xAI, an AI company founded by Elon Musk. It may not be making waves in the AI landscape, but it’s still getting a lot of media coverage, so it’s worth knowing about.
Gemini Pro currently powers some queries on Bard, Google’s chatbot, and is available to developers through Google AI Studio or Vertex AI. The Gemini Nano and Ultra are scheduled to launch in 2024.
follow me : Twitter, Facebook, LinkedIn, Instagram