Introduction: What is deep learning?
Deep learning is a subset of machine learning and is basically a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain, but they fall far short of the human brain’s ability to “learn” from large amounts of data. Although single-layer neural networks can provide rough predictions, adding hidden layers can improve optimization and accuracy.
Deep learning is an artificial intelligence (AI) technique that teaches computers to process data in ways inspired by the human brain. Deep learning models can recognize complex patterns in images, text, audio, and other data to generate accurate insights and predictions.
How does deep learning work?
Deep-learning neural networks, or artificial neural networks, attempt to mimic the human brain through a combination of data inputs, weights, and biases. These elements work together to accurately identify, classify, and describe the objects in your data.
Deep neural networks consist of multiple layers of interconnected nodes, each layer building on the previous layer to refine and optimize predictions and classifications. This progression of calculations through the network is called forward propagation. The input and output layers of deep neural networks are called view layers. The input layer is where the deep learning model takes the data to process, and the output layer is where the final prediction or classification is made.
Another process called backpropagation uses algorithms such as gradient descent to calculate the prediction error and adjust the weights and biases of the function by moving layers backward to train the model. Forward propagation and backpropagation together allow the neural network to make predictions and correct errors accordingly. Over time, the algorithm becomes progressively more accurate.
The simplest types of deep neural networks have been described above in the simplest terms. However, deep learning algorithms are very complex, and different types of neural networks exist to address specific problems and datasets. For example,
- Convolutional neural networks (CNNs), used primarily in computer vision and image classification applications, can detect features and patterns within an image, enabling tasks like object detection or recognition. In 2015, CNN bested a human in an object recognition challenge for the first time.
- Recurrent neural network (RNNs) are typically used in natural language and speech recognition applications as it leverage sequential or time-series data.
Deep learning applications
Real-world deep learning applications are a part of our daily lives, but in most cases, they are so well-integrated into products and services that users are unaware of the complex data processing that is taking place in the background. Some of these examples include the following:
Law enforcement
Deep learning algorithms analyze and learn from transaction data to identify dangerous patterns that indicate potential fraudulent or criminal activity. Speech recognition, computer vision and other deep learning applications can improve the efficiency and effectiveness of investigative analysis by extracting patterns and evidence from audio and video recordings, images and documents, allowing law enforcement agencies to analyze your data faster and more accurately. Can help to do.
Financial services
Financial institutions regularly use predictive analytics to drive algorithmic trading of stocks, assess business risks for loan approvals, detect fraud, and help manage credit and investment portfolios for clients.
Customer service
Many organizations are incorporating deep learning technology into their customer service processes. Chatbots used in various applications, services, and customer service portals are a simple form of AI. Traditional chatbots use natural language and visual recognition, often found in menus or call centers. However, more advanced chatbot solutions attempt to use learning to determine whether ambiguous questions have multiple answers. Based on the responses received, the chatbot will attempt to answer these questions directly or escalate the conversation to the human user.
Virtual assistants such as Apple’s Siri, Amazon Alexa, and Google Assistant extend the chatbot concept by enabling voice recognition capabilities. This creates new ways to engage users in a personalized way.
Healthcare
The healthcare industry has greatly benefited from deep learning capabilities since the digitization of hospital records and images. Image recognition applications support medical imaging professionals and radiologists, allowing them to analyze and evaluate more images in less time.
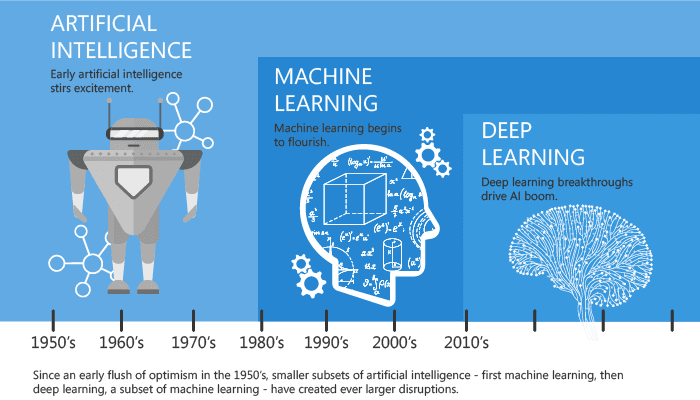
The History of Deep Learning
The origins of deep learning and neural networks can be traced back to British mathematician and computer scientist Alan Turing’s prediction of the existence of supercomputers with human-like intelligence in the future and scientists’ early understanding of the human brain. The 1950s is when we started experimenting with simulation. Below is a good summary of how this process works, courtesy of the extremely clever MIT Technology Review.
The program maps a set of virtual neurons and assigns random numbers, or “weights,” to the connections between them. These weights indicate that each simulated neuron has 0. Decide how to respond with a mathematical output from 1 to 1. The sound of a syllable in spoken language. Programmers train neural networks to detect objects and tones by bombarding the network with digitized versions of images containing objects and tones.
If the network fails to accurately recognize a particular pattern, the algorithm adjusts the weights. The ultimate goal of this training was to enable the network to consistently recognize a set of sound patterns and images that we humans know, such as the sound “d” and images of dogs. This is much like how children learn what a dog is by observing details such as the head shape and behavior of cute, barking animals that other people call dogs.
Here’s a quick look at the history of deep learning and some of the formative moments that shaped the technology into what it is today.
In the early 1980s, John Hopfield’s recurrent neural networks made headlines, followed by NetTalk, a program developed by Terry Szenowski that could pronounce English words.
RISE OF NEURAL NETWORKS AND BACKPROPAGATION
In 1986, Carnegie Mellon University professor and computer scientist Jeffrey Hinton (now a researcher at Google and long known as the “godfather of deep learning”), one of several researchers who, scientifically speaking, described neural networks as who helped make it cool again, showing that it’s more than just a problem. There are very few things that can be trained using backpropagation to improve shape recognition and word prediction. Hinton coined the term “deep learning” in 2006.
After Yann LeCun invented a machine that could read handwritten numbers, many discoveries followed, most of which went unnoticed by the world. Hinton and Laken were recently among three AI pioneers to win the 2019 Turing Award.
BREAKTHROUGH AND WIDESPREAD ADOPTION
As is the case now, the media is focusing on stories that audiences can relate to, such as the computer that learned to play backgammon, IBM’s Deep Blue’s defeat of world chess champion Garry Kasparov, and IBM’s Watson’s dominance over Jeopardy. A big focus was placed on easy-to-use development.
By 2012, deep learning was already being used to help people turn left in Albuquerque (Google Street View) and to query the estimated average airspeed of an unladen swallow (Apple’s Siri). It was used. In June of that year, Google connected 16,000 computer processors, provided Internet access, and taught a machine how to identify cats (by watching millions of randomly selected YouTube videos). I saw. But what might seem ridiculously simple was actually a pretty shocking development in science.
Despite this impressive feat, which proves that deep learning programs are growing faster and more accurate, Google researchers admit that this is just the beginning and the tip of the iceberg.
“It is worth noting that our network is still small compared to the human visual cortex, which is a million times larger in terms of the number of neurons and synapses,” the researchers wrote.
About four months later, Hinton and a team of graduate students won a competition sponsored by the pharmaceutical giant Merck. The software that won the top honor used deep learning to find the most effective drugs from an incredibly small dataset that “describes the chemical structures of thousands of different molecules.” People were appropriately impressed by this important discovery in pattern recognition, which can also be applied to other areas such as marketing and law enforcement.
“The point of this approach is that it scales beautifully,” Hinton told the Times. “Basically, you just have to keep making it bigger and faster, and it will get better. You can’t look back now.”
Neural Networks and Deep Learning
What is Neural Network?
Neural networks are a set of algorithms based on the human brain and designed to recognize patterns. They interpret sensory data through a type of machine recognition, labeling, or clustering of raw inputs. The patterns they recognize are numbers, contained in vectors, and all real-world data, including images, audio, text, and time series, must be converted into vectors.
Neural networks are useful for clustering and classification. You can think of these as clustering and classification layers on top of the data you store and manage. They are useful for grouping unlabeled data based on similarity between sample inputs and for classifying data if you have a labeled dataset to train. (Neural networks can also extract features that are fed into other algorithms for clustering and classification. Therefore, deep neural networks can be used to build larger machines, including reinforcement learning, classification, and regression algorithms.) Contains. It can be considered as a component of a learning application.
Artificial neural networks are the basis of large-scale language models (LLMS) used in Chat GPT, Microsoft’s Bing, Google’s Bard, and Meta’s Llama.
To know the answer, you need to ask a few questions: During deep learning, what problems will arise? And more importantly, can you solve this?
- Which results are important? In a classification problem, these results are labels that can be applied to the data. For example, Spam or Not Spam for email filtering, Good Guy or Bad Guy for fraud detection, Angry Customer or Happy Customer for customer relationship management, etc. Other types of problems include anomaly detection (useful for fraud detection and predictive maintenance of manufacturing equipment) and clustering, which is useful for recommendation systems that highlight similarities.
- Do you have the right data? For example, if you have a classification problem, you will need labeled data. Is the required dataset publicly available, or can it be created (using a data annotation service like Scala or AWS Mechanical Turk)? In this example, the spam email is labeled as spam, and that label allows the algorithm to map the input to the classification of interest. You don’t know if you have the right data until you actually have it. If you’re a data scientist working on a problem, you can’t rely on anyone to tell you whether your data is good enough or not. To answer this question, we need to examine the data directly.
Classification
All classification tasks depend on labeled datasets. In other words, for a neural network to learn the relationship between labels and data, humans must transfer the knowledge to the dataset. This is known as supervised learning.
- Recognize faces, recognize people in images, and recognize facial expressions (anger, happiness).
- Recognize objects in images (stop signs, pedestrians, lane markers, etc.).
- Recognize gestures in videos
- Detect speech, identify speakers, convert speech to text, and recognize emotions in speech.
- Classify text as spam (for email) or fraud (for insurance claims). Recognize emotions in text (customer feedback)
Any label that a human can generate that is a result of the interest associated with the data can be used to train a neural network.
Clustering
Clustering, or grouping, is to find similarities. Deep learning does not require labels to detect similarities. Learning without adding labels is called unsupervised learning. Unlabeled data constitutes the bulk of the world’s data. One of the rules of machine learning is that the more data an algorithm can be trained on, the more accurate the algorithm will be. Therefore, unsupervised learning has the potential to produce highly accurate models.
Anomaly detection: Another aspect of similarity detection is detecting anomalies, or unusual behavior. Abnormal behavior is often closely related to something that needs to be detected and prevented, such as fraud.
Predictive Analytics: Regressions
For example, classification allows deep learning to establish relationships between pixels in an image and a person’s name. This can also be called static prediction. Similarly, when exposed to enough relevant data, deep learning can establish connections between current and future events. You can do regression between the past and future. Upcoming events are like labels in a way. Deep learning doesn’t necessarily care about time or the fact that something hasn’t happened yet. Given a time series, deep learning reads a series of numbers and predicts what the next number is most likely to be.
- Hardware failure (data center, manufacturing, transportation)
- Deterioration in health status (stroke or heart attack based on vital statistics and wearable data)
- Customer churn (predicting the likelihood of customer abandonment based on web activity and metadata)
- Employee turnover rate (same for employees)
The more we can predict, the more we can prevent. As you can see, neural networks are leading us to a world with fewer surprises. There aren’t any surprises, but there are a few. We are also moving towards a world of smart agents that combine neural networks with other algorithms, such as reinforcement learning, to achieve their goals.
With a quick overview of deep learning use cases, let’s see what a neural net is made of.
Neural Network Elements
Deep learning is the name we use for “stacked neural networks.”. In other words, the network is made up of many layers.
A layer is made up of nodes. Nodes are simply places where computations occur, are loosely patterned on neurons in the human brain, and fire when encountered with sufficient stimulation. A node associates an input from the data with a set of coefficients or weights that enhance or attenuate that input, giving importance to the input in relation to the task the algorithm is trying to learn. For example, which inputs are most useful for classifying the data without error? The products of these inputs and weights are summed, and the sum is passed to the so-called activation function of the node to produce the final result (e.g., classification actuation) that determines what affects the signal. How far it must travel in the network to determine if the signal is passed, causing the neuron to “fire.”.
Here’s a picture of what a node looks like:
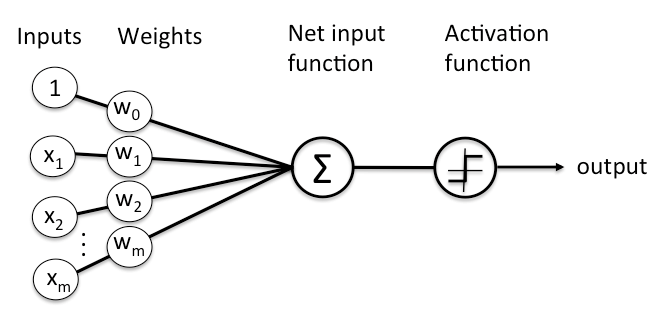
A node layer is a row of those neuron-like switches that turn on or off as the input is fed through the net. Each layer’s output is simultaneously the subsequent layer’s input, starting from the initial input layer receiving your data.
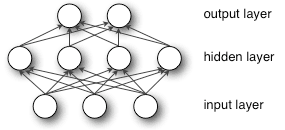
Pairing the model’s adjustable weights with input features is how we assign significance to those features with regard to how the neural network classifies and clusters input.
Related Topic:
- What is natural language processing?
- What is artificial intelligence? Definition, top 10 types and examples
- What is artificial intelligence (AI)? How many types of AI are there, and how many courses are in AI?
Key Concepts of Deep Neural Networks
Deep learning networks are distinguished from more general single-hidden-layer neural networks by their depth. That is, the data must pass through a number of node layers in the multi-step process of pattern recognition.
Previous versions of neural networks, such as the first perceptron, were shallow, consisting of one input layer, one output layer, and at most one hidden layer in between. Three or more layers (including input and output) qualify as “deep” learning. “Very deep” isn’t just a buzzword used by algorithms to make you think you’re reading Sartre or listening to some band you’ve never heard of. This is a strictly defined term and refers to multiple hidden layers.
In a deep learning network, each layer of nodes trains a different set of features based on the output of the previous layer. The deeper you go into the neural network, the more complex the features a node can recognize become as it aggregates and recombines features from previous layers.
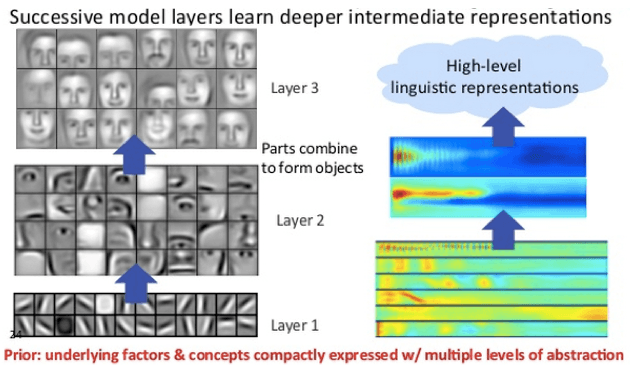
This is known as the functional hierarchy, which is a hierarchy of increasing complexity and abstraction. This allows deep learning networks to handle very large, high-dimensional data sets that contain billions of parameters passed through nonlinear functions.
Among other things, these neural networks can discover latent structure in unlabeled, unstructured data, which makes up the majority of the world’s data. Another term for unstructured data is raw media. That means photos, text, video, and audio recordings. Therefore, one of the problems that can be most effectively solved by deep learning is processing raw, unlabeled media from around the world, clustering it, and giving it data and names that humans have never before organized into relational databases. not done. The aim is to identify similarities and discrepancies in the data.
For example, deep learning can take a million images and cluster them according to similarity, such as a cat in one corner, an icebreaker in another, and all of your grandmother’s photos in the third. This is the basis of so-called smart photo albums.
Let’s apply this same idea to other data types. Deep learning has the ability to cluster raw text, such as emails or news articles. Emails filled with angry complaints may accumulate in one corner of the vector space, while satisfied customers or spambot messages may accumulate in another corner. It is the basis for various messaging filters and can be used in customer relationship management (CRM). The same applies to voice messages.
In a time series, data can be clustered around normal/healthy behavior and abnormal/dangerous behavior. When time-series data is generated by a smartphone, it can provide information about the user’s health and habits. If produced by auto parts, it can be used to prevent catastrophic failure.
Unlike most traditional machine learning algorithms, deep learning networks perform feature extraction automatically without human intervention. Given that feature extraction is a task that can take a team of data scientists years to complete, deep learning is one way to overcome the challenge of limited expertise. It empowers small data science teams that are inherently non-scalable.
When trained on unlabeled data, each layer of nodes in a deep network repeatedly attempts to recreate the input from which it samples, thereby improving the network’s inferences and probability distributions of the input data. The difference between them is reduced. It learns the characteristics by automatically trying to suppress them. For example, restricted Boltzmann machines perform so-called reconstructions in this way.
Additionally, these neural networks learn to recognize correlations between certain relevant features and optimal outcomes. That is, it builds relationships between feature signals and what those features represent, whether it is a full reconstruction or labeled data.
When applied to unstructured data, deep learning networks trained on labeled data have access to far more inputs than machine learning networks. This is a recipe for better performance. The more data the net can be trained on, the more accurate the net can be. (A bad algorithm trained on a large amount of data can perform better than a good algorithm trained on a small amount of data.) Deep learning’s ability to learn by processing large amounts of unlabeled data, compared to previous algorithms. Provides clear benefits.
Deep learning networks end with an output layer, which is a logistic or softmax classifier that assigns a probability to a particular outcome or label. It is called prophecy, but in a broader sense, it is prophecy. Given raw data in the form of an image, a deep learning network can determine, for example, that the input data has a 90% chance of representing a person.
Neural Networks & Artificial Intelligence
In some circles, neural networks are synonymous with AI. It can also be considered a “brute force” method characterized by a lack of intelligence, as it involves starting from a blank slate and creating an accurate model. According to this interpretation, neural networks, while effective, are inefficient approaches to modeling because they make no assumptions about functional dependencies between outputs and inputs.
Not surprisingly, cutting-edge AI research groups are pushing the boundaries of the field by training increasingly large neural networks. Brute force works. This is a necessary, if not sufficient, condition for AI breakthroughs. OpenAI’s more general AI activities emphasize brute force approaches, which have proven effective with well-known models such as GPT-3.
Algorithms such as Hinton’s capsule network require very few examples of data to convert into an accurate model. In other words, the current research has the potential to solve the brute inefficiencies of deep learning.
Neural networks are useful as function approximators that map inputs to outputs in many perceptual tasks to achieve more general intelligence, but they can also be combined with other AI methods to perform more complex tasks. You can do it too. For example, deep reinforcement learning incorporates neural networks within the framework of reinforcement learning to map actions to rewards for achieving a goal. DeepMind’s victories in the video game and board game Go are a good example of this.
FAQs
What are the three types of deep learning?
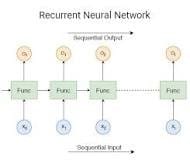
The following three types of deep neural networks are popularly used today:
- Multi-Layer Perceptrons (MLP)
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
Why do we need deep learning?
Deep learning models can be trained to perform classification tasks and recognize patterns in photos, text, audio, and many other types of data. It is also used to automate tasks that typically require human intelligence, such as describing images or transcribing audio files.
What are the hardware requirements for deep learning?
Deep learning requires enormous amounts of computing power. High-performance graphics processing units (GPUs) are ideal because they can handle large amounts of computation across multiple cores with plenty of memory. However, managing multiple GPUs on-premises places a high demand on internal resources and can be very expensive to scale.
What are the 4 pillars of deep learning?
The four pillars of deep learning are:
- Artificial neural networks
- Backpropagation
- Activation functions and gradient descent
Who invented deep learning?
The first breakthrough in deep learning occurred in the mid-1960s, when the Soviet mathematician Alexey Ivakunenko (with the help of colleague V.G. Lapa) created a small but functional neural network.
What is a deep learning algorithm?
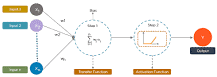
Deep learning models are trained using neural network architectures or sets of labeled data containing multiple layers. Sometimes even exceeding human-level performance. These architectures learn features directly from the data without intervening in manual feature extraction.
follow me : Twitter, Facebook, LinkedIn, Instagram
15 thoughts on “Ultimate Guide: What is Deep Learning?”
Comments are closed.