
What is machine learning?
Machine learning is a branch of artificial intelligence (AI) and computer science that focuses on using data and algorithms to mimic the way humans learn and gradually improve their accuracy.
Many innovative products are based on machine learning and advanced technology, like Netflix, self-driving cars.
Machine learning is a component of data science. Machine learning performs statistical methods, algorithms, and predictions with the help of data mining. Data mining is basically used in data science.
Machine learning algorithms are written in the Python programming language and platform using TensorFlow and PyTorch for solution development.
Machine learning provide ability to machine that can learn from data and identifying patterns and predictions. Machine learning has become essential solving problems in big areas, like:
- Computational Finance (Credit Scoring, Algorithmic Trading)
- Computer vision (facial recognition, motion tracking, object detection)
- Computational biology (DNA sequencing, brain tumor detection, drug discovery)
- Automotive, Aerospace, and Manufacturing (Predictive Maintenance)
- Natural Language Processing (Speech Recognition)
Types of Machine Learning
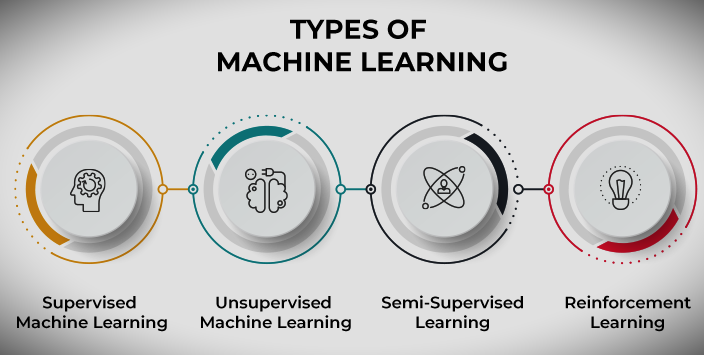
Machine learning can be categorized in many ways, but based on its behavior, it can be categorized into four main types:
1. Supervised machine learning
Supervised machine learning defined the labeled datasets to train the algorithm that provides accurate prediction outputs. When input data is fed into the model, model adjust the weight until good weight achieved. This process is called cross-validation process, and the model does not overfit or underfit. Techniques for supervised learning include neural networks, naive bayers, linear regression, and support vector machines (SVMs).
This type of ML involves supervision, where a machine is trained on a labeled dataset and is able to predict outputs based on the training provided. A labeled dataset specifies that certain input and output parameters are already mapped. Therefore, the machine is trained using inputs and corresponding outputs. The subsequent step uses the test dataset to build a tool that predicts the outcome.
For example, consider an input dataset of images of parrots and crows. First, the machine is trained to understand images of parrots and crows, including their color, eyes, shape, and size. After training, an input image of the parrot is provided, and the machine is expected to identify the objects and predict the output. The trained machine examines various features of the object in the input image, such as color, eyes, shape, etc., to make the final prediction. This is the process of object recognition in supervised machine learning.
The main goal of supervised learning techniques is to map input variables to output variables. Supervised machine learning is divided into two broad categories.
1. Classification
It refers to algorithms that solve classification problems when the output variables are categorical. For example, yes or no, true or false, male or female. The practical application of this category is evident in spam detection and email filtering. Classification algorithms include random forest algorithms, decision tree algorithms, logistic regression algorithms, and support vector machine algorithms.
2. Regression
Regression algorithms handle regression problems when input and output variables have a linear relationship. These are known to predict continuous output variables. Examples include weather forecasting, market trend analysis, etc. Common regression algorithms include simple linear regression algorithms, multivariate regression algorithms, decision tree algorithms, and Lasso regression.
2. Unsupervised machine learning
Unsupervised learning refers to an unsupervised learning method. Here, the machine is trained using an unlabeled dataset, allowing it to predict outputs without supervision. The goal of unsupervised learning algorithms is to group unclassified datasets based on similarities, differences, and patterns in their inputs.
Unsupervised machine learning analyzes unlabeled datasets called clusters. These algorithm discover the hidden clusters in data without human intervention. This method is used in data analysis, customer segmentation, and image recognition. and its similarity and deference between the information. Another algorithm used in unsupervised machine learning is k-means clustering.
For example, consider an input dataset of images of containers containing fruits. Here, the image is not known to the machine learning model. When you input a dataset into an ML model, the job of the model is to identify patterns in objects such as color, shape, and differences found in the input images and classify them. After classification, the machine predicts the output when tested using the test dataset.
Unsupervised machine learning is further divided into two types.
1. Clustering
The clustering technique refers to grouping objects into groups based on parameters such as similarities and differences between objects. For example, group customers based on the products they purchase. Clustering algorithms include the k-means clustering algorithm, mean-shift algorithm, DBSCAN algorithm, principal component analysis, and independent component analysis.
2. Association
Association learning refers to identifying specific relationships between variables in large datasets. Determine the dependencies between different data items and map-related variables. Typical applications include web usage mining and market data analysis. Common algorithms that follow association rules include the Apriori algorithm, the Eclat algorithm, and the FP-growth algorithm.
3. Semi-supervised learning
Semi-supervised learning provides a good intermediate between supervised and unsupervised learning. During training, a smaller labeled data set is used to guide classification and feature extraction from a larger unlabeled data set. Semi-supervised learning can solve the problem of not having enough labeled data for supervised learning algorithms. It is also useful when labeling enough data would be too expensive.
Semi-supervised learning has the characteristics of both supervised and unsupervised machine learning. Train the algorithm using a combination of labeled and unlabeled datasets. By using both types of datasets, semi-supervised learning overcomes the shortcomings of the above options.
Consider the example of college students. When students learn concepts under the supervision of a teacher in college, it is called supervised learning. In unsupervised learning, students study the same concepts at home without the guidance of a teacher. On the other hand, it is a semi-supervised learning form where students revise the concepts after learning under the guidance of a teacher at the university.
4. Reinforcement learning
Reinforced machine learning is a machine learning model similar to supervised learning, but the algorithm is not trained using sample data. This model learns through trial and error. A set of successful results is enriched to develop optimal recommendations and policies for a specific problem.
Reinforcement-based learning is a feedback-based process. Here, the AI component uses a hit-and-trial approach to automatically sense its surroundings, take action, and learn from experience to improve performance. Constituents are rewarded for every good action and punished for every wrong move. Therefore, the components of reinforcement learning aim to maximize rewards by doing good things.
Unlike supervised learning, reinforcement learning does not contain labeled data, and the agent learns only through experience. Consider video games. Here, the game specifies the environment, and each behavior of the reinforcement agent defines its state. Agents are entitled to receive feedback through penalties and rewards, which affect the overall game score. The ultimate goal of the agent is to get high scores.
Reinforcement learning is applied in various fields, such as game theory, information theory, and multi-agent systems. Reinforcement learning is further divided into two types of methods, or algorithms.
- Positive reinforcement learning: This refers to adding a strong stimulus after a particular behavior of the agent. This increases the likelihood that the behavior will occur again in the future (for example, by adding a reward after the behavior).
- Negative Reinforcement Learning: Negative reinforcement learning refers to reinforcing certain behaviors that avoid negative consequences.
How does machine learning work?
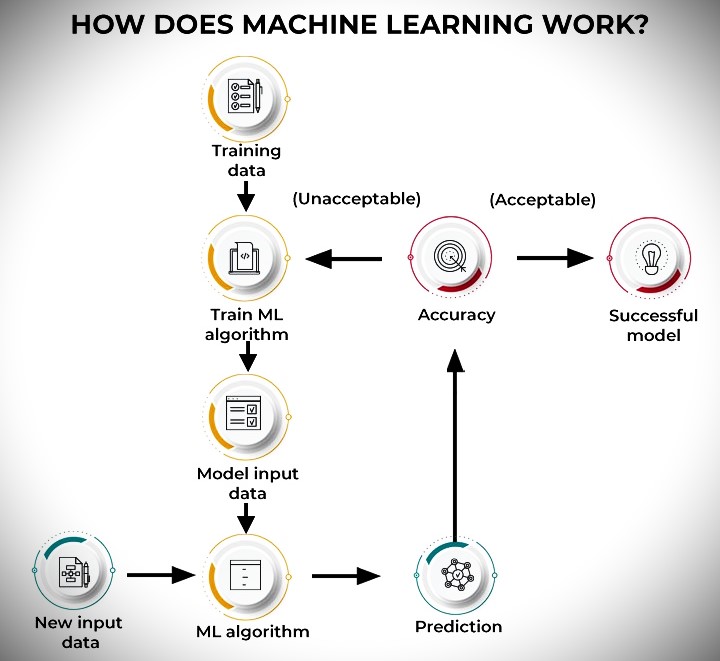
Machine learning check the accuracy of the prediction. Machine learning deployed extended datasets until the accuracy achieved.
The training system for machine learning algorithms into three main parts.
1. Decision-Making Process
Generally, machine learning algorithms are used to make predictions or classifications. It is based on the labeled or unlabeled data input data.
2. Error Function
The error function evaluates the predictions of the model. If you have known examples, you can evaluate the accuracy of your model by comparing it with the error function.
3. Model optimization process
If the model fits the data points in the training set better, the weights are adjusted to reduce the difference between the known examples and the model’s predictions. The algorithm repeats this iterative “evaluate and optimize” process, automatically updating the weights until the accuracy threshold is met.
General Machine Learning Algorithms
Several machine-learning algorithms are commonly used. These include:
- Neural Networks: Neural networks use large numbers of linked processing nodes to simulate how the human brain works. Neural networks excel at pattern recognition and play an important role in applications such as natural language translation, image recognition, speech recognition, and image generation.
- Linear Regression: This algorithm is used to predict numbers based on linear relationships between different values. For example, this technique can be used to predict home prices based on historical data for the area.
- Logistic Regression: This supervised learning algorithm predicts categorical response variables, such as yes/no answers to questions. It can be used for purposes such as spam classification and production line quality control.
- Clustering: Using unsupervised learning, clustering algorithms can identify patterns in data and group the data. Computers can assist data scientists by identifying differences between data items that humans have overlooked.
- Decision Trees: Decision trees can be used to predict numbers (regression) and classify data into categories. Decision trees use a branching sequence of connected decisions that can be represented in a dendrogram. One advantage of decision trees is that they are easy to verify and audit, unlike the black boxes of neural networks.
- Random Forest: In a random forest, a machine learning algorithm combines the results of multiple decision trees to predict a value or range.
Examples of machine learning
Here are some examples of machine learning that you may encounter on a daily basis.
- Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition, or speech-to-text, is the ability to translate human speech into written form using natural language processing (NLP). Many mobile devices have voice recognition built into their systems to perform voice searches. Improve accessibility to Siri—or text messages.
- Customer Service: Online chatbots are replacing human agents in the customer journey and changing the way we think about customer engagement on websites and social media platforms. Chatbots answer frequently asked questions (FAQs) on topics like shipping and provide personalized advice, product cross-selling, and sizing suggestions. Examples include virtual agents on e-commerce sites. Messaging bot using Slack and Facebook Messenger. The tasks are usually performed by virtual or voice assistants.
- Computer Vision: This AI technology allows computers to derive meaningful information from digital images, videos, and other visual inputs and take appropriate actions. Computer vision powered by convolutional neural networks is used in photo tagging in social media, radiology imaging in medicine, self-driving cars in the automotive industry, and much more.
- Recommendation Engine: AI algorithms use historical consumer behavior data to help discover data trends that can be used to develop more effective cross-selling strategies. Recommendation engines are used by online retailers to recommend relevant products to customers during the checkout process.
- Robotic Process Automation (RPA): Also known as software robotics, RPA uses intelligent automation technology to perform repetitive manual tasks.
- Automated Stock Trading: AI-powered high-frequency trading platforms designed to optimize stock portfolios execute thousands or even millions of trades per day without human intervention.
- Fraud detection: Banks and other financial institutions can use machine learning to identify suspicious transactions. Supervised learning allows you to train a model using information about known fraudulent transactions. Anomaly detection allows you to identify transactions that seem unusual and deserve further investigation.
Top 5 Machine Learning Applications
Industries that handle large amounts of data are recognizing the importance and value of machine learning technology. Machine learning derives insights from data in real time, allowing organizations that use it to work more efficiently and gain an advantage over their competitors.
In this fast-paced digital world, every industry is greatly benefiting from machine learning technology. Here we take a look at the top five ML application areas.
1. Healthcare Industry
Machine learning is increasingly being applied in the healthcare industry thanks to wearable devices and sensors, such as wearable fitness trackers and smart health watches. All such devices monitor users’ health data to assess their health status in real time.
Additionally, machine learning is making significant contributions in two areas:
- Drug discovery: Creating or discovering new drugs is an expensive and lengthy process. Machine learning can help speed up the steps involved in such multi-step processes.
- Personalized treatment: Pharmaceutical companies face the difficult challenge of validating the effectiveness of specific drugs for large populations. This is because the drug is only effective in a small group of people in clinical trials and may cause side effects in some subjects.
ML technology discovers markers of patient response by analyzing individual genes and providing targeted therapies to patients.
2. Financial Sector
Many financial institutions and banks are now using machine learning techniques to combat fraud and gain important insights from large amounts of data. Insights derived from ML can help identify investment opportunities and help investors decide when to trade.
Additionally, data mining techniques can help cyber surveillance systems focus on warning signs of fraudulent activity and subsequently neutralize it. Some financial institutions are already partnering with technology companies to take advantage of machine learning.
3. Retail Sector
Retail websites use machine learning extensively to recommend products based on a user’s purchasing history. Retailers use ML technology to capture and analyze data to provide personalized shopping experiences to customers. We also apply ML to marketing campaigns, customer insights, customer product planning, and price optimization. Some everyday examples of recommendation systems include:
- When you browse products on Amazon, the product recommendations you see on the homepage are generated by machine learning algorithms. Amazon uses artificial neural networks (ANN) to provide intelligent, personalized recommendations that are relevant to customers based on their recent purchase history, comments, bookmarks, and other online activity.
- Netflix and YouTube rely heavily on recommendation systems that suggest shows and videos to users based on their viewing history.
Additionally, retail sites are also equipped with virtual assistants and conversational chatbots that leverage ML, natural language processing (NLP), and natural language understanding (NLU) to automate the customer shopping experience.
4. Travel industry
Machine learning is playing a pivotal role in expanding the scope of the travel industry. Rides offered by Uber, Ola, and even self-driving cars have a robust machine learning backend.
Consider Uber’s machine learning algorithm that handles the dynamic pricing of their rides. Uber uses a machine learning model called ‘Geosurge’ to manage dynamic pricing parameters. It uses real-time predictive modeling on traffic patterns, supply, and demand. If you are getting late for a meeting and need to book an Uber in a crowded area, the dynamic pricing model kicks in, and you can get an Uber ride immediately but would need to pay twice the regular fare.
Moreover, the travel industry uses machine learning to analyze user reviews. User comments are classified through sentiment analysis based on positive or negative scores. This is used for campaign monitoring, brand monitoring, compliance monitoring, etc., by companies in the travel industry.
5. Social media
With machine learning, billions of users can efficiently engage on social media networks. Machine learning is pivotal in driving social media platforms,, from personalizing news feeds to delivering user-specific ads. For example, Facebook’s auto-tagging feature employs image recognition to identify your friend’s face and tag them automatically. The social network uses ANN to recognize familiar faces in users’ contact lists and facilitates automated tagging.
Similarly, LinkedIn knows when you should apply for your next role, whom you need to connect with, and how your skills rank compared to peers. All these features are enabled by machine learning.
Related Topics You should know about:
- What is artificial intelligence (AI)? How many types of AI are there, and how many courses are in AI?
- What is artificial intelligence? Definition, top 10 types and examples
- What is natural language processing?
- What is deep learning?
- Top 10 Best Topics for Research in Artificial Intelligence
- What is a chatbot? Definition, Working, Types, and Examples
- ChatGPT (Chat Generative Pre-Trend Transformer).
- What is conversational AI? Definition, types and example
follow me : Twitter, Facebook, LinkedIn, Instagram
23 thoughts on “What is Machine Learning applications? definition, and best real life examples”
Comments are closed.